A Step-by-Step Guide to Extracting Data from PDFs with ChatGPT
Efficiently extract structured data from PDFs with ChatGPT. Learn the steps to streamline PDF parsing in this guide.


PDF files are everywhere these days, used for everything from academic papers to business contracts. But getting data out of PDFs can be a real headache. Traditional methods like manual entry or basic software tools can be slow and prone to errors, especially if you're dealing with a lot of data or a mix of text and images.
That's where ChatGPT comes in. This AI tool uses Natural Language Processing (NLP) to make it easier and more accurate to get data from PDFs. You don't need to be a tech expert to use it, which is great news for people who are new to data processing.
In this article, we'll guide you through using ChatGPT to extract data from PDFs. We'll cover how it works, any limitations you should be aware of, and alternative methods. By the end, you'll have a clear idea of how to use this tool effectively for your data extraction tasks.
Extract data from PDFs into Structured Format with ChatGPT
There are several ways to extract data from PDFs into structured JSON format with ChatGPT. With these various options available, users can choose the method that best suits their needs and preferences for PDF parsing with ChatGPT.
There are multiple methods to use ChatGPT for pulling data from PDFs and converting it into a structured format. In this guide, we'll focus on two main options.
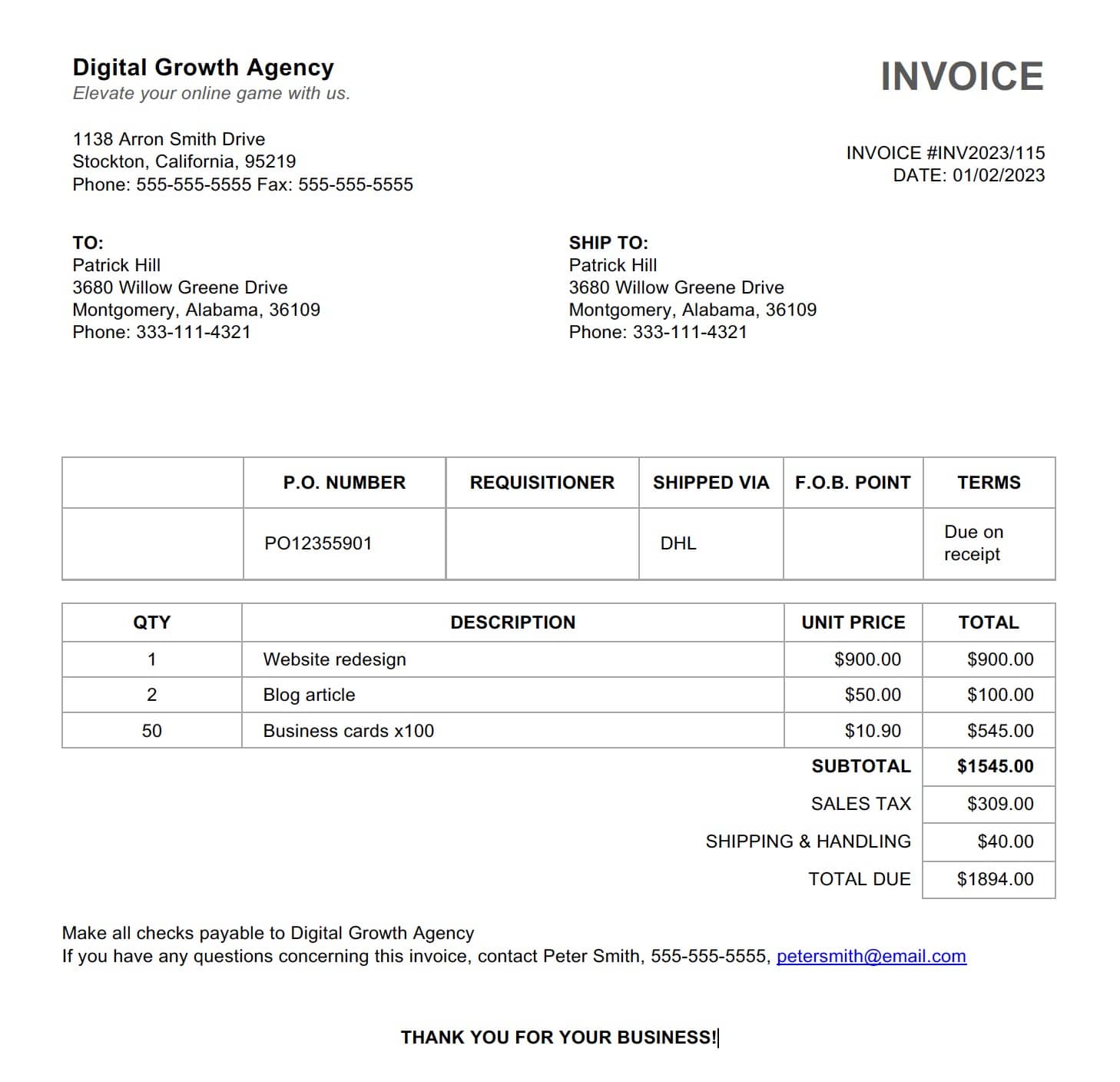
Here's a sample invoice that we'll use in this article to demonstrate how to extract data using ChatGPT.
Option 1: Copy and Paste Text From PDF
For PDFs that are text-based, searchable, and between 1-3 pages with a simple layout, this is your easiest option for data extraction. All you need to do is copy the content from the PDF and paste it into ChatGPT, along with a prompt for extraction.
In our case, the data can be easily copied from our invoice while preserving basic formatting:
Digital Growth Agency
Elevate your online game with us.
1138 Arron Smith Drive
Stockton, California, 95219
Phone: 555-555-5555 Fax: 555-555-5555
INVOICE
INVOICE #INV2023/115
DATE: 01/02/2023
TO:
Patrick Hill
3680 Willow Greene Drive
Montgomery, Alabama, 36109
Phone: 333-111-4321
SHIP TO:
Patrick Hill
3680 Willow Greene Drive
Montgomery, Alabama, 36109
Phone: 333-111-4321
P.O. NUMBER REQUISITIONER SHIPPED VIA F.O.B. POINT TERMS
PO12355901 DHL Due on
receipt
QTY DESCRIPTION UNIT PRICE TOTAL
1 Website redesign $900.00 $900.00
2 Blog article $50.00 $100.00
50 Business cards x100 $10.90 $545.00
SUBTOTAL $1545.00
SALES TAX $309.00
SHIPPING & HANDLING $40.00
TOTAL DUE $1894.00
Make all checks payable to Digital Growth Agency
If you have any questions concerning this invoice, contact Peter Smith, 555-555-5555, [email protected]
THANK YOU FOR YOUR BUSINESS!Raw invoice data
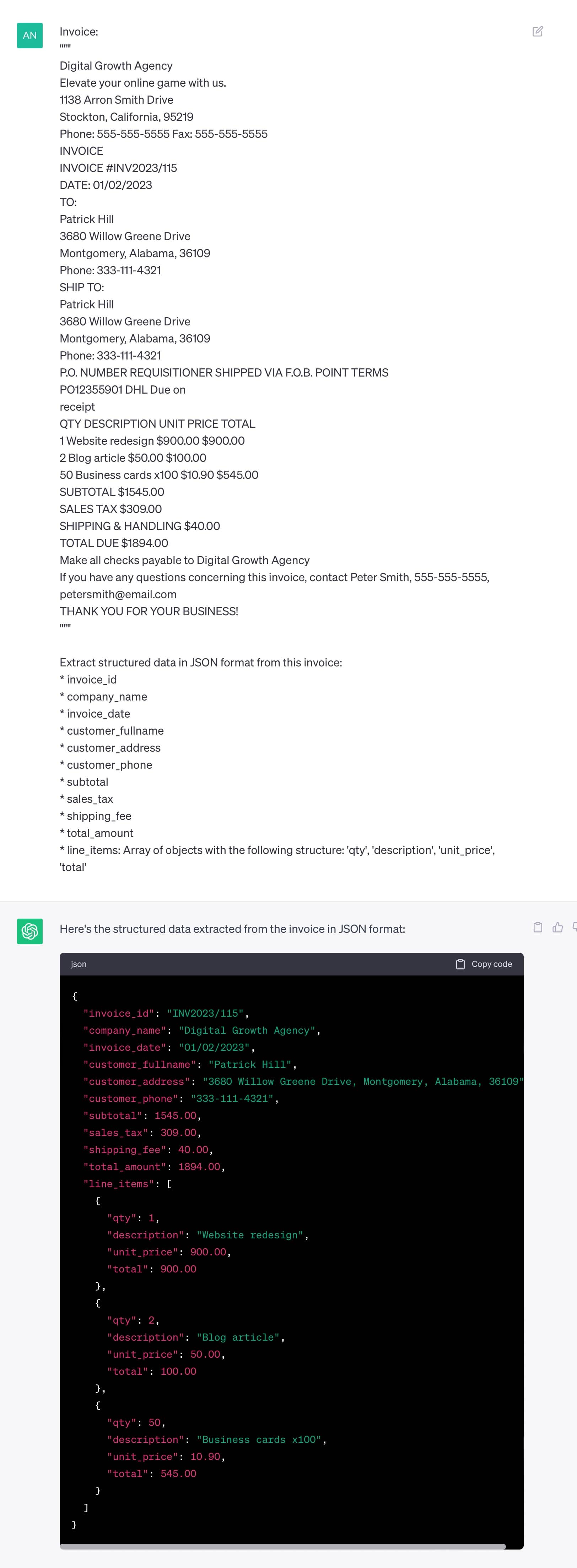
Let's convert this invoice data into a JSON format. We use ChatGPT with GPT-3.5 for this.
The prompt to ChatGPT can be simple, like:
Extract structured data in JSON format from this invoice:
* invoice_id
* company_name
* invoice_date
* customer_fullname
* customer_address
* customer_phone
* subtotal
* sales_tax
* shipping_fee
* total_amount
* line_items: Array of objects with the following structure: 'qty', 'description', 'unit_price', 'total'ChatGPT will quickly pull the data and format it into a clean JSON structure, creating an array for line items from the invoice:
{
"invoice_id": "INV2023/115",
"company_name": "Digital Growth Agency",
"invoice_date": "01/02/2023",
"customer_fullname": "Patrick Hill",
"customer_address": "3680 Willow Greene Drive, Montgomery, Alabama, 36109",
"customer_phone": "333-111-4321",
"subtotal": 1545.00,
"sales_tax": 309.00,
"shipping_fee": 40.00,
"total_amount": 1894.00,
"line_items": [
{
"qty": 1,
"description": "Website redesign",
"unit_price": 900.00,
"total": 900.00
},
{
"qty": 2,
"description": "Blog article",
"unit_price": 50.00,
"total": 100.00
},
{
"qty": 50,
"description": "Business cards x100",
"unit_price": 10.90,
"total": 545.00
}
]
}
Screenshot:
Next, you can ask ChatGPT to turn these line items into a table:
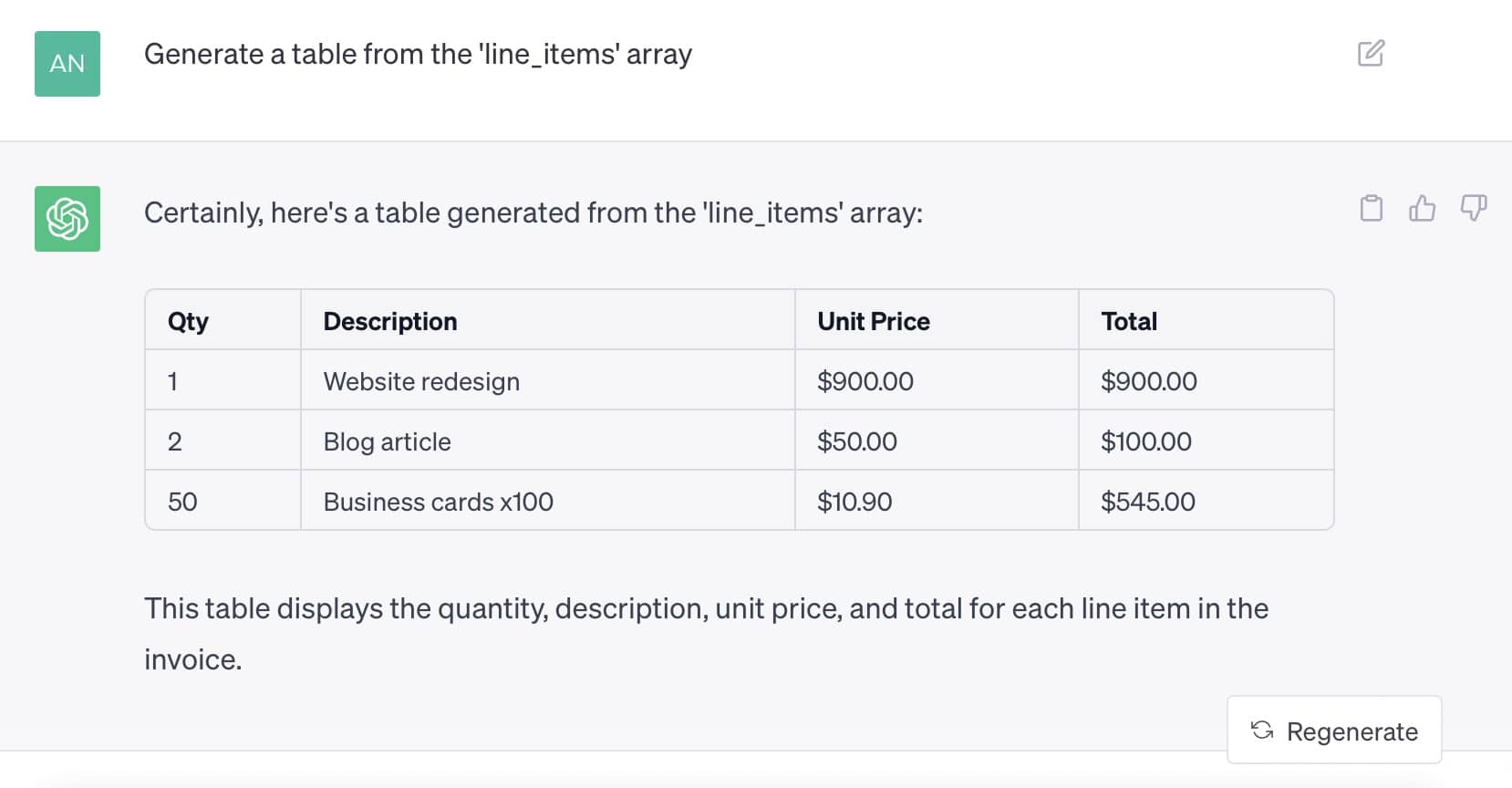
Invoice line items converted into a table
Or even create a CSV format:
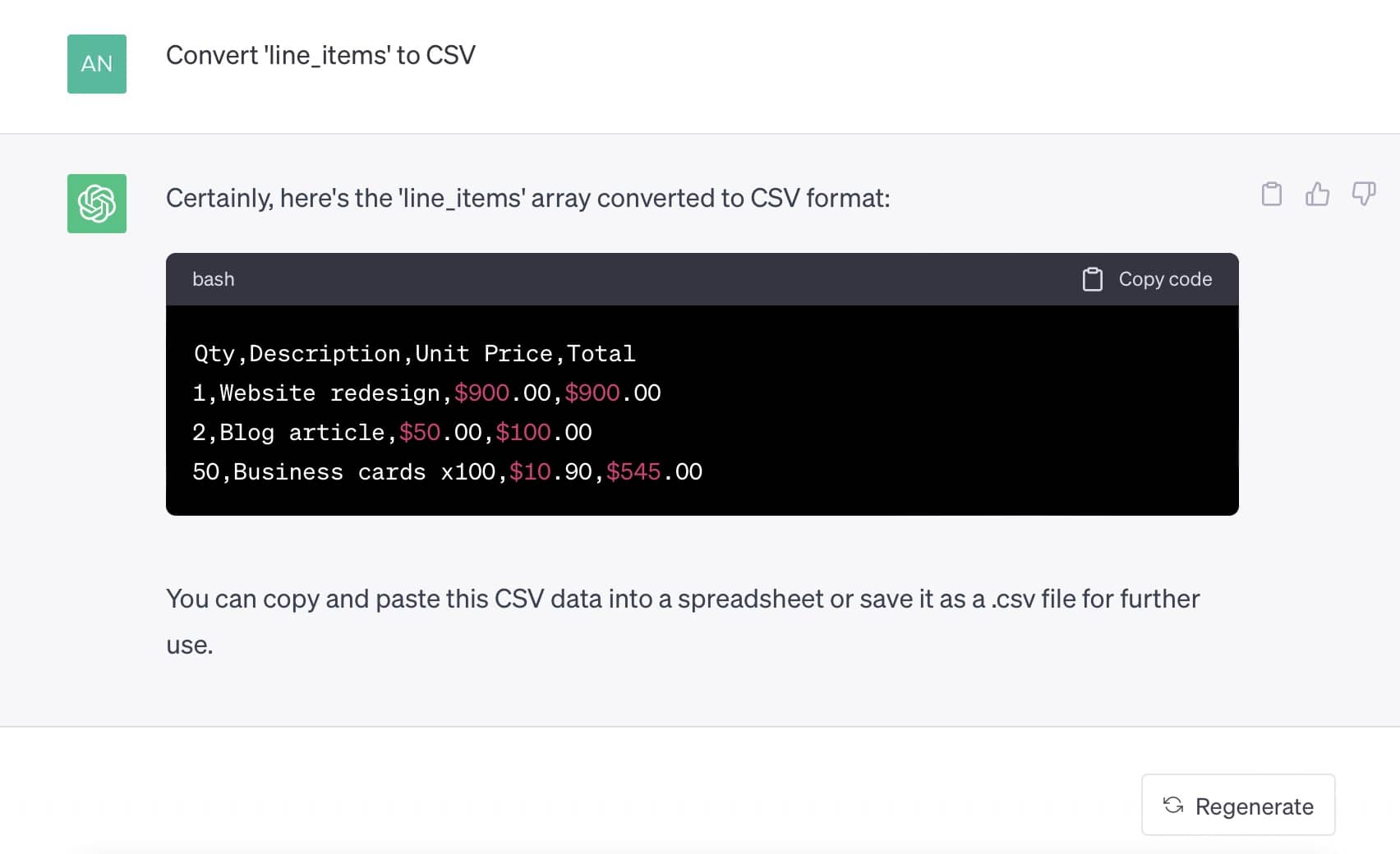
Real-world invoices often comprise multiple pages of data, making this method incredibly helpful. The formatted data can be easily imported into tools such as Google Sheets, Excel, or accounting software.
Option 2: Using GPT-4 Advanced Data Analysis (beta)
The GPT-4 with "Advanced Data Analysis (beta)" option enables a more advanced data extraction method. Previously, you couldn't upload or download anything in ChatGPT, but Advanced Data Analysis changes that.
We'll instruct ChatGPT to generate code for reading PDFs and converting them to JSON. ChatGPT will generate and execute this code using its Code Interpreter. That's where the magic happens.
Now, let's dive in. Here's the prompt we've crafted for ChatGPT:
Use the pdfplumber library to read the attached PDF and extract the 'line_items' from this invoice as a JSON array of objects with the following fields: 'qty', 'description', 'unit_price', 'total'.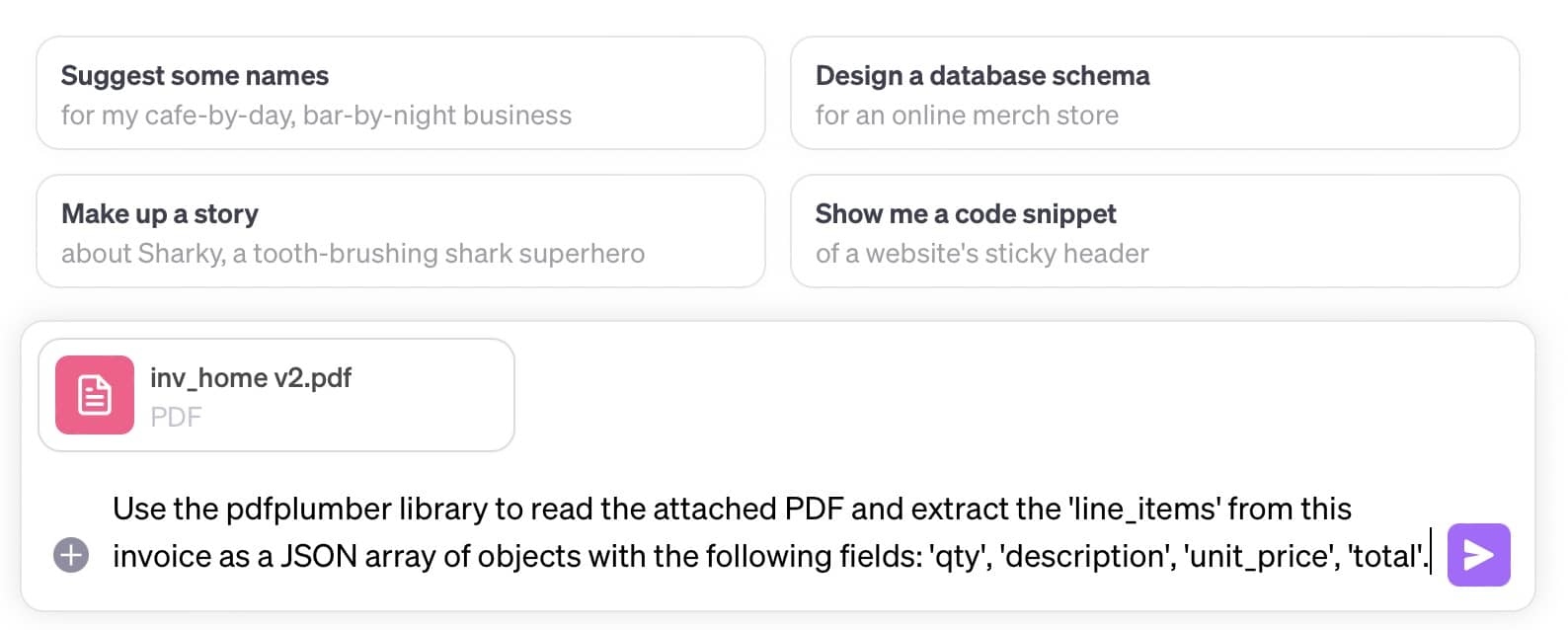
We intentionally recommend using the pdfplumber library because we've observed that when ChatGPT uses a different library, it often leads to errors during execution.
To start, ChatGPT generates and executes code using the requested pdfplumber Python library. It successfully extracts text data from the uploaded PDF.
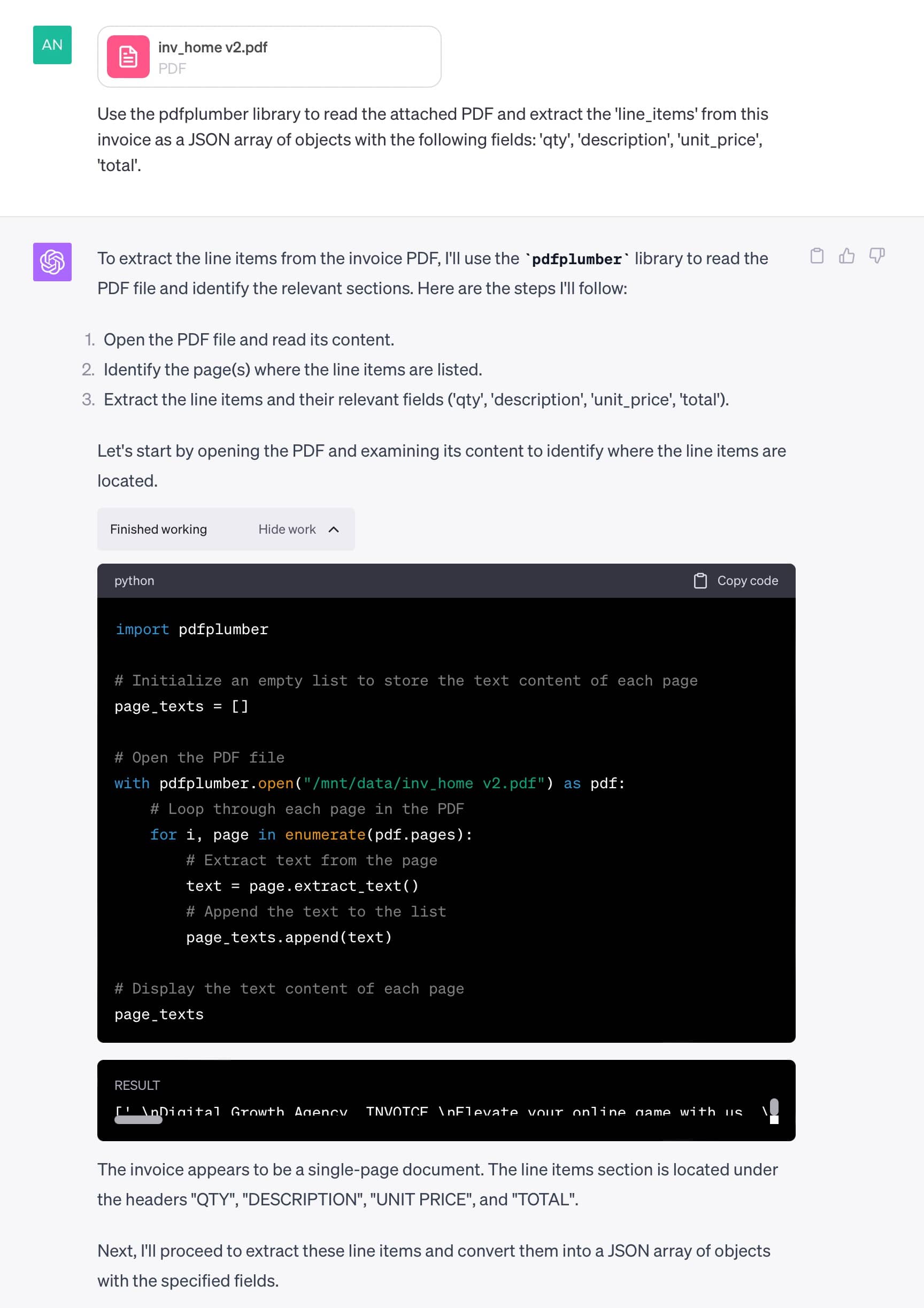
Next, it generates a regular expression and successfully extracts line items.

Finally, it formats and outputs the extracted JSON.
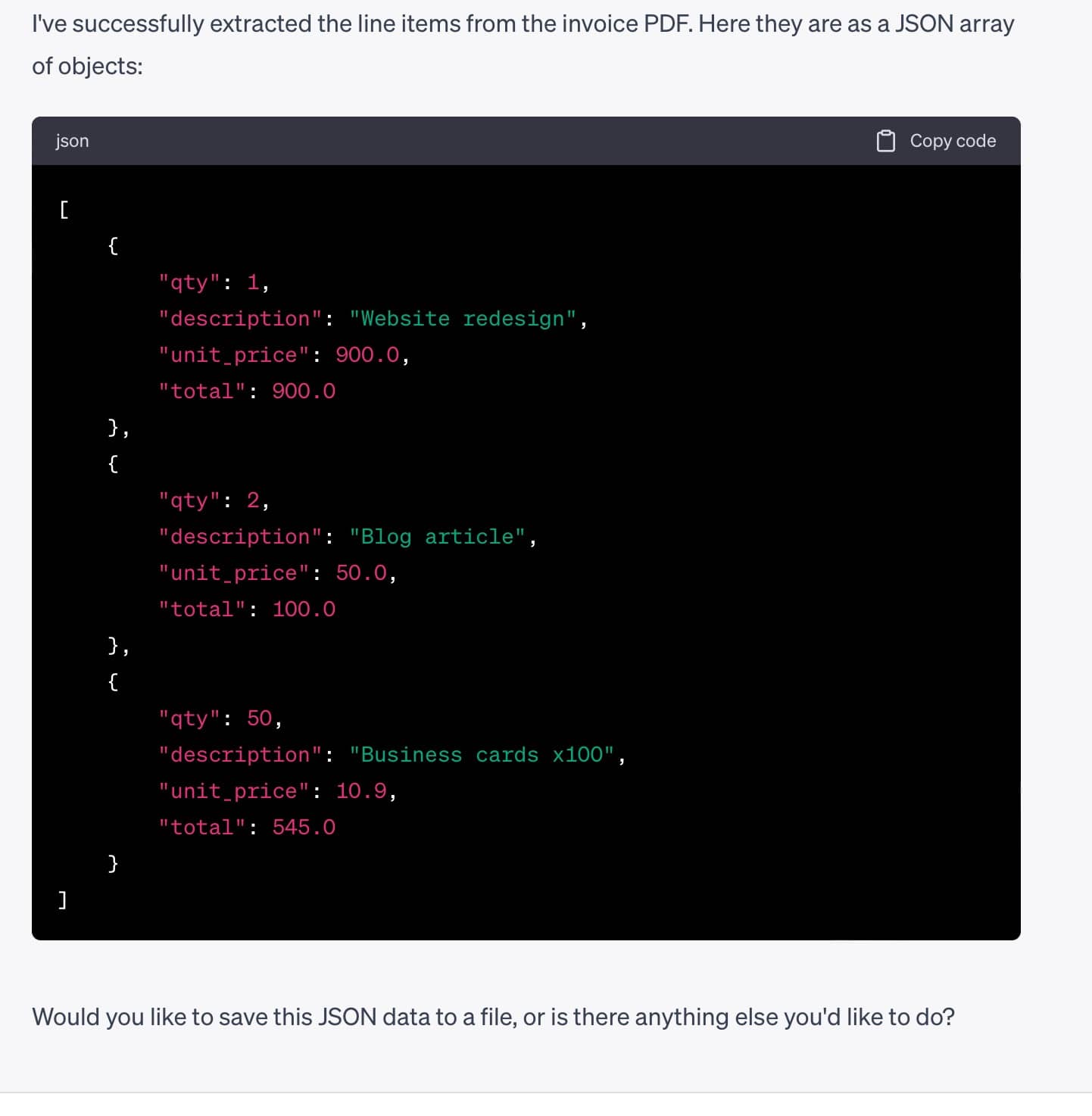
Limitations of Using ChatGPT for PDF Data Extraction
While ChatGPT has positioned itself as a transformative tool in many applications, its use in extracting data from PDFs is not without limitations. It's essential for businesses and individual users to be aware of these pitfalls before integrating ChatGPT into their PDF processing workflow.
1) Manual Uploads Required
The tool doesn’t scale effectively for bulk operations. Each PDF has to be uploaded manually or you need to copy/paste the content of your PDF (as described in option 1), which can be cumbersome when dealing with large numbers of files.
2) Lack of Built-in Integrations
There's no straightforward method to automatically channel the extracted data into CRM, accounting software, or applications like Google Sheets. Such integrations are vital for businesses looking to streamline their workflow.
3) Challenges With Large-Scale PDF Processing
For businesses looking to perform in-depth analysis using extracted data, the minor errors produced by ChatGPT can be significant obstacles. The tool's tendency to 'hallucinate' data, or introduce elements not originally in the source, can make the analysis even more challenging.
4) Memory of Previous Prompts
ChatGPT has been observed to remember previous prompts on occasion, which can lead to mixups in subsequent data extraction tasks, potentially affecting the quality of the extracted data.
5) Human Supervision Required
ChatGPT isn't flawless. Its outputs often need human review to guarantee accuracy. This is particularly vital in critical fields like healthcare, where an incorrect piece of information could lead to severe consequences.
6) Privacy and Security Concerns
Any data provided to ChatGPT, whether through prompts or uploaded files, may potentially be used in its training. This raises clear data privacy concerns, especially with sensitive information. OpenAI's data usage policy does indicate that personal data is not used to enhance the model, but the mere transmission of such data over the web interface can be a concern for many.
7) Complex Format Handling
ChatGPT often struggles with intricately formatted PDFs, especially when they contain non-text elements like tables, graphs, or images. Even if it can provide descriptions of such elements, replicating their exact format can be a challenge.
Parsing PDF files Using Airparser
In the realm of data extraction from PDFs, the limitations of tools like ChatGPT can be substantial, especially for business and professional use cases. If you are looking for a powerful solution that can help you overcome the inaccuracies and errors of ChatGPT, Airparser is the software you can look at. It is specifically designed to quickly and accurately extract data from any PDF document, regardless of its complexity.

Addressing the Limitations of ChatGPT
Airparser effectively resolves many of the drawbacks associated with other methods. Unlike ChatGPT, Airparser eliminates concerns about data usage for model training, thus ensuring enhanced privacy and security. Let's examine some key features of Airparser that can help you overcome ChatGPT's challenges more closely.
- Airparser utilizes advanced OCR technology to extract data from scanned PDFs, which ensures accurate parsing even for these types of documents.
- It offers both manual and automated upload options so that you can choose the method that best suits your needs.
- Airparser integrates seamlessly with other tools and platforms, which makes it even easier to incorporate PDF paring into existing workflows.
- This software employs industry-leading security measures to protect user data and ensuring privacy and compliance with relevant regulations.
- Airparser is designed to handle complex PDF formats, including those with non-standard layouts or formatting.
- Airparser is optimized for large-scale PDF processing. It means that with advanced algorithms, Airparser will ensure fast and accurate parsing even for large datasets.
How Airparser Works to Parse PDFs?
Using Airparser is incredibly straightforward. Follow the coming instructions to extract PDF files with Airparser:
1) Forward PDFs: Forward emails and attachments directly to Airparser’s inbox. You can also manually upload files, import your documents using API, or an automation platform, such as Zapier or Make.

2) Automated Extraction: After uploading the files, create an extraction schema to describe the data you need to extract. Airparser instantly goes to work, extracting data seamlessly.
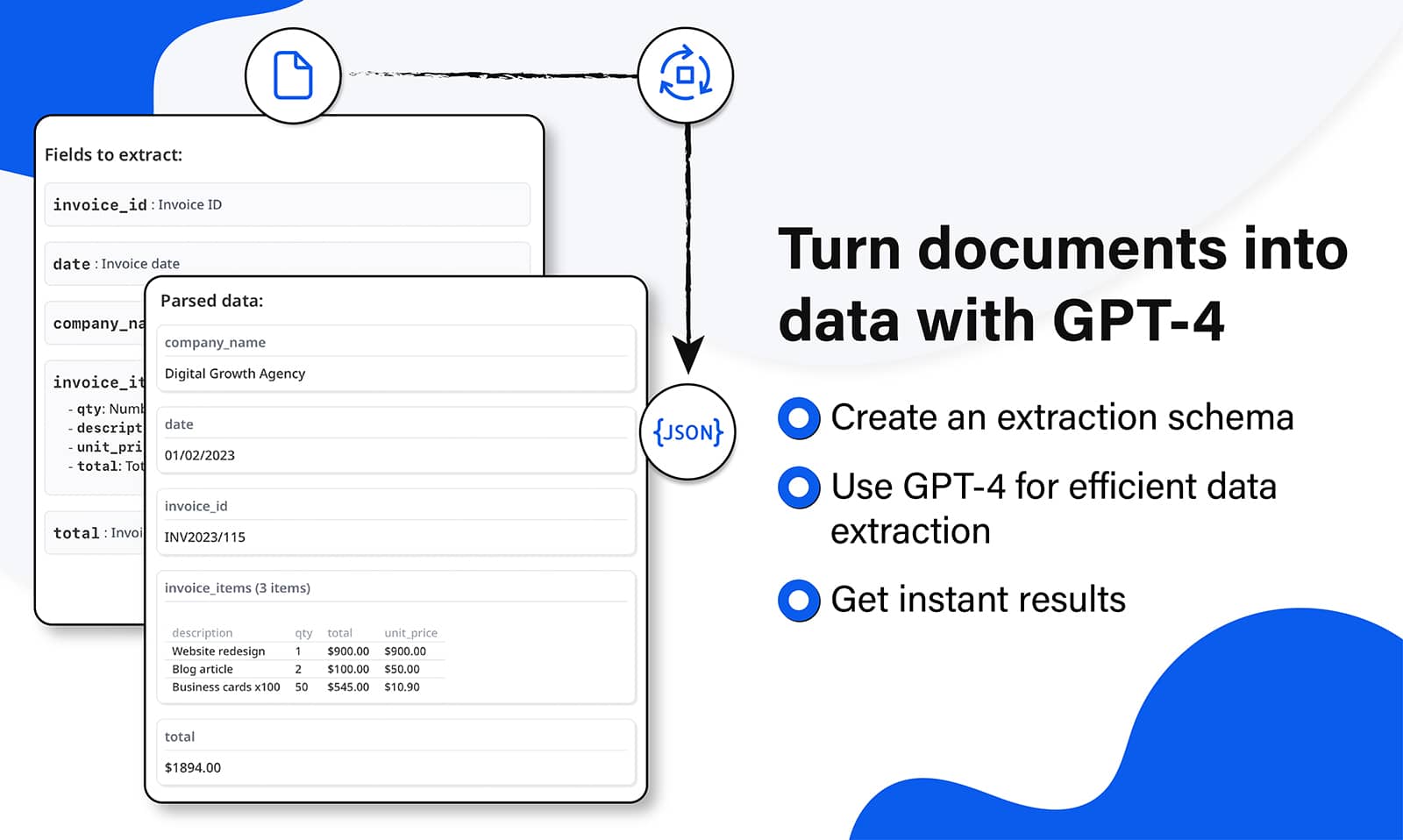
3) Integration Capabilities: The tool offers integration with platforms like Google Sheets, various accounting software, and other applications. It facilitates data export through webhooks, Zapier, and Make, automating data management workflows.

Airparser: Broad Spectrum of Use Cases
- Emails and Attachments: Apart from PDFs, Airparser supports emails and their attachments. Users can directly forward them to the platform for quick parsing.
- OCR Capabilities: Airparser’s OCR engine can process scanned documents, handwritten notes, and images, transforming them into actionable, structured data. This means even scanned invoices and handwritten texts are no longer a challenge.
- Human-Generated Texts: The tool can easily extract information such as signatures, dates, and key details from human-written emails and texts.
- Invoices and Receipts: It's perfect for businesses, enabling efficient extraction of amounts, vendor details, dates, and itemized lists from invoices, receipts, and purchase orders.
- CVs and Resumes: For HR professionals, Airparser can swiftly extract names, contact details, and work experience from candidates’ CVs and resumes.
- Contracts: The platform automates the extraction of terms, parties, and other crucial data from contracts, simplifying contract management processes.
- Order Confirmations: Businesses can streamline their order processing by extracting critical information like order numbers, items purchased, and delivery details from confirmation documents.