Vision vs Text in LLM Document Parsing: How to Choose the Right Engine
Learn when to use Vision, Text, or Hybrid engines for LLM-powered document parsing. Compare accuracy, performance, and real-world use cases.



As AI transforms document parsing, businesses now have access to two powerful modalities for data extraction: Vision-based and Text-based parsing. These approaches both leverage large language models (LLMs), but operate on different inputs—images vs. text—and are optimized for different types of documents.
Understanding when to use each engine is critical for achieving reliable, high-quality extractions. In this guide, we’ll walk through the differences between Vision and Text parsing, share insights from our experience building Airparser (an LLM-powered document parser), and provide practical advice to help you choose the right engine.
Whether you're processing scanned PDFs, contracts, research papers, invoices, or emails, this guide will help you make better parsing decisions.
Vision vs Text Parsing Explained
Text-based Parsing
Text-based parsing begins by converting documents into machine-readable text using OCR (Optical Character Recognition). Once the text is extracted, an LLM analyzes the content to identify and extract structured data.
- Input: OCR-generated plain text
- Process: LLM works only on the text layer
- Strengths: Fast, low latency, and efficient for long, structured text
Vision-based Parsing
Vision parsing skips OCR and instead lets the LLM analyze the visual layout directly—working with the document as an image. This approach leverages Vision-Language Models (VLMs) trained to understand document structure visually.
- Input: Entire document as an image
- Process: LLM reads layout, positioning, font styles, tables, etc.
- Strengths: Superior for short, image-based, or layout-heavy documents
Both modes are supported in Airparser, and choosing the right one can significantly improve accuracy and reliability.
When to Use Vision vs Text
Use Text Engine When:
- The document is long and text-heavy (e.g. contracts, equity notes, research papers)
- It is digitally generated (e.g. PDFs with selectable text, Word, HTML)
- You need faster processing and scalability
- Layout is linear with few visual elements
Use Vision Engine When:
- The document is a short scan or image (e.g. ≤3 pages)
- The layout is visually complex: tables, stamps, multi-column
- It’s an image format (.jpg, .png, scanned PDF)
- OCR output is fragmented or low quality
Consider Hybrid (Vision + Text) When:
- You need layout understanding and clean text extraction
- The document is complex (e.g. HTML emails, stylized reports, web pages)
Comparison Table
| Feature | Text Engine | Vision Engine | Hybrid |
|---|---|---|---|
| Input Format | OCR-extracted or native text | Visual (image of document) | Text + image |
| Accuracy (complex docs) | Good | Excellent | Best of both |
| Speed & Cost | Fast & cost-effective | Slower & compute-heavy | Slower, higher context cost |
| Best For | Long reports, emails | Scans, Excel, stamped docs | Web/emails with layout |
| Handles Tables | Basic | Excellent | Excellent |
| Handles Layout | Limited | High | High |
Airparser Benchmarks and Insights
At Airparser, we evaluated both modes across a wide range of real-world use cases. Here are some of our takeaways:
Case: Scanned Utility Bills (2 pages)
- Text Engine: Missed key fields like billing tables and fine-print notes.
- Vision Engine: Successfully captured all layout details, including headers, tables, and labels.
Case: Long Contract PDFs (10+ pages)
- Text Engine: Fast, reliable parsing of paragraphs, clauses, and dates.
- Vision Engine: Slower, less efficient for dense text with minimal layout.
Case: HTML Emails
- Text Engine: Quick extraction of sender details, dates, and CTAs.
- Vision Engine: Better for styled elements, branding, and email signatures.
- Hybrid: Combined approach works best for maintaining layout and precision.
Case: Excel and Tables
- Text Engine: Struggles with cell alignment and multi-row entries.
- Vision Engine: Reads visual spacing and structure effectively.
How to Choose the Right Engine in Airparser
In Airparser, you choose the parsing engine—Vision, Text, or Hybrid—when you create a new Inbox. Here’s how to select the right engine for your use case:
Step 1: Create a New Inbox
Start by creating a new Inbox. This is where your documents will be parsed. During setup, you'll be asked to choose the engine that best suits your document type.
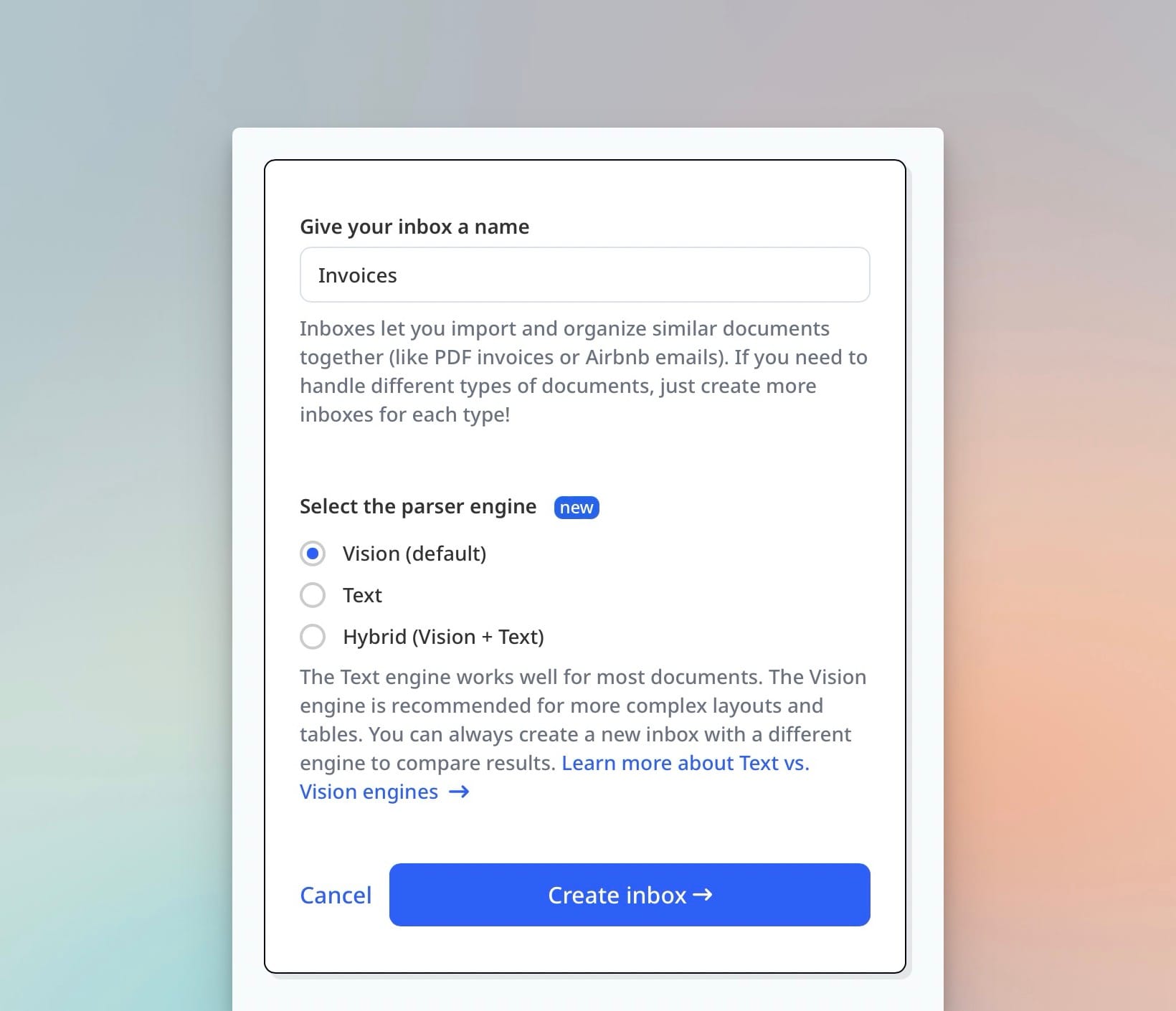
- Text engine is ideal for long, structured documents (e.g. contracts, reports).
- Vision engine works better for short, scanned, or visually complex documents.
- Hybrid mode is helpful for HTML emails, web pages, or cases where layout matters as much as text content.
Step 2: Upload Documents
Once your Inbox is created, upload your documents for testing. Use a mix of typical and edge-case files to evaluate performance.
Step 3: Preview and Refine
Airparser shows a real-time preview of extracted fields. You can edit the schema, adjust field names, or add missing ones. The engine will adapt based on your input.
Step 4: Improve Over Time
You can switch engines anytime or duplicate the Inbox to try a different approach. Airparser adapts and improves with every correction you make.
This flexibility ensures you're always using the most effective parsing engine for your workflow.
Final Thoughts
Choosing between Vision, Text, or Hybrid parsing isn’t just a technical toggle — it’s a strategic decision that affects data quality, automation, and downstream workflows.
At Airparser, we recommend:
- Text engine for long, text-heavy digital documents such as contracts, research papers, and structured reports.
- Vision engine for short documents with complex visual layouts like scanned PDFs, tables, and image-based forms.
- Hybrid engine for HTML emails, web pages, or documents where both visual structure and clean text extraction are essential.
Making the right choice early can save hours of post-processing and boost data accuracy dramatically.
Want to try both modes? Start parsing with Airparser!