How to Make a PDF Searchable (Free OCR Tool)
Convert scanned PDFs into searchable documents using our free OCR tool. Upload your PDF, detect text automatically, and download a searchable PDF in seconds.


Many PDF files are actually just images of text.
This usually happens when a document is scanned using a scanner or phone camera. The result looks like a normal PDF, but the text inside cannot be searched, copied, or highlighted.
If you try to press Ctrl + F, nothing happens. You also cannot copy and paste text from the document.
The solution is OCR (Optical Character Recognition). OCR technology analyzes the image and detects the characters inside it. Then it adds a hidden text layer to the PDF.
In this guide, you'll learn how to convert scanned PDFs into searchable PDFs using a free OCR tool.
What is a searchable PDF?
A searchable PDF is a PDF file that contains a hidden text layer behind the document image.
This means the PDF still looks exactly the same, but the computer can recognize the text inside it.
With a searchable PDF, you can:
- search for words using Ctrl + F
- copy and paste text
- highlight sentences
- extract data from the document
- index the document for search systems
Without OCR, a scanned PDF is simply an image.
Here is the difference:
| PDF Type | Description |
|---|---|
| Scanned PDF | Contains only images of pages |
| Searchable PDF | Contains images + hidden text layer |
The OCR process detects text inside the images and embeds that text inside the PDF.
Why some PDFs are not searchable
Many PDFs are not searchable because they were created from scanned documents.
When you scan a document, the scanner does not understand the text. It simply takes a photo of the page.
Common examples include:
- scanned contracts
- scanned invoices
- scanned receipts
- faxed documents
- archived paper records
- photographed documents
These files look like normal PDFs, but they behave like images.
Typical problems include:
- text cannot be selected
- text cannot be copied
- Ctrl + F search does not work
- automation tools cannot extract data
OCR solves this problem by converting the image content into readable text.
How to make a PDF searchable
Turning a scanned PDF into a searchable document is a simple process.
The typical workflow looks like this:
- Upload the scanned PDF
- Run OCR on the document
- OCR detects characters in the image
- A hidden text layer is added
- Download the new searchable PDF
The final document keeps the original layout, but now the text inside the file becomes searchable and selectable.
You can convert your document using this free tool: https://ocr.airparser.com/searchable-pdf
Free tool: convert PDF to searchable PDF
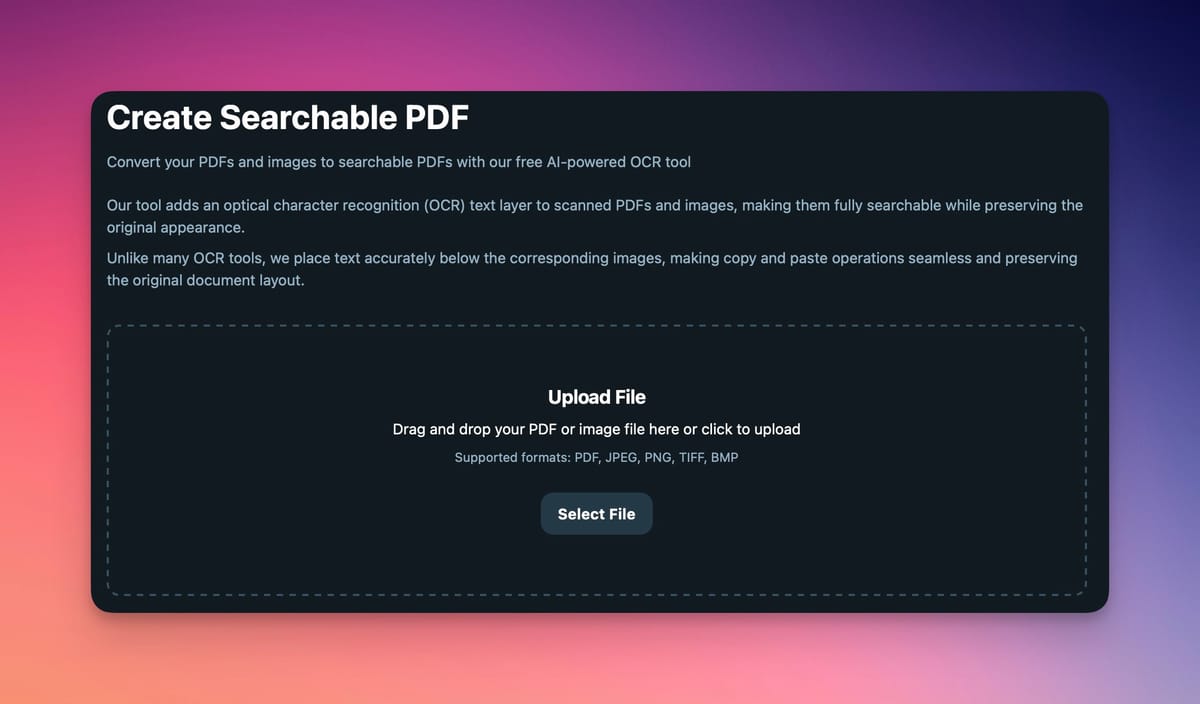
The Airparser OCR tool allows you to convert scanned PDFs and images into searchable PDFs in seconds.
It works by applying optical character recognition (OCR) to your document and embedding the recognized text inside the file.
The result is a PDF that looks identical to the original but contains a searchable text layer.
The tool supports several file formats, including:
- JPG
- PNG
- TIFF
It also preserves the original layout of the document so the text remains aligned with the scanned image.
You can convert your document using this free tool:
https://ocr.airparser.com/searchable-pdf
Step-by-step guide
Below is a simple guide showing how to convert a scanned document into a searchable PDF.
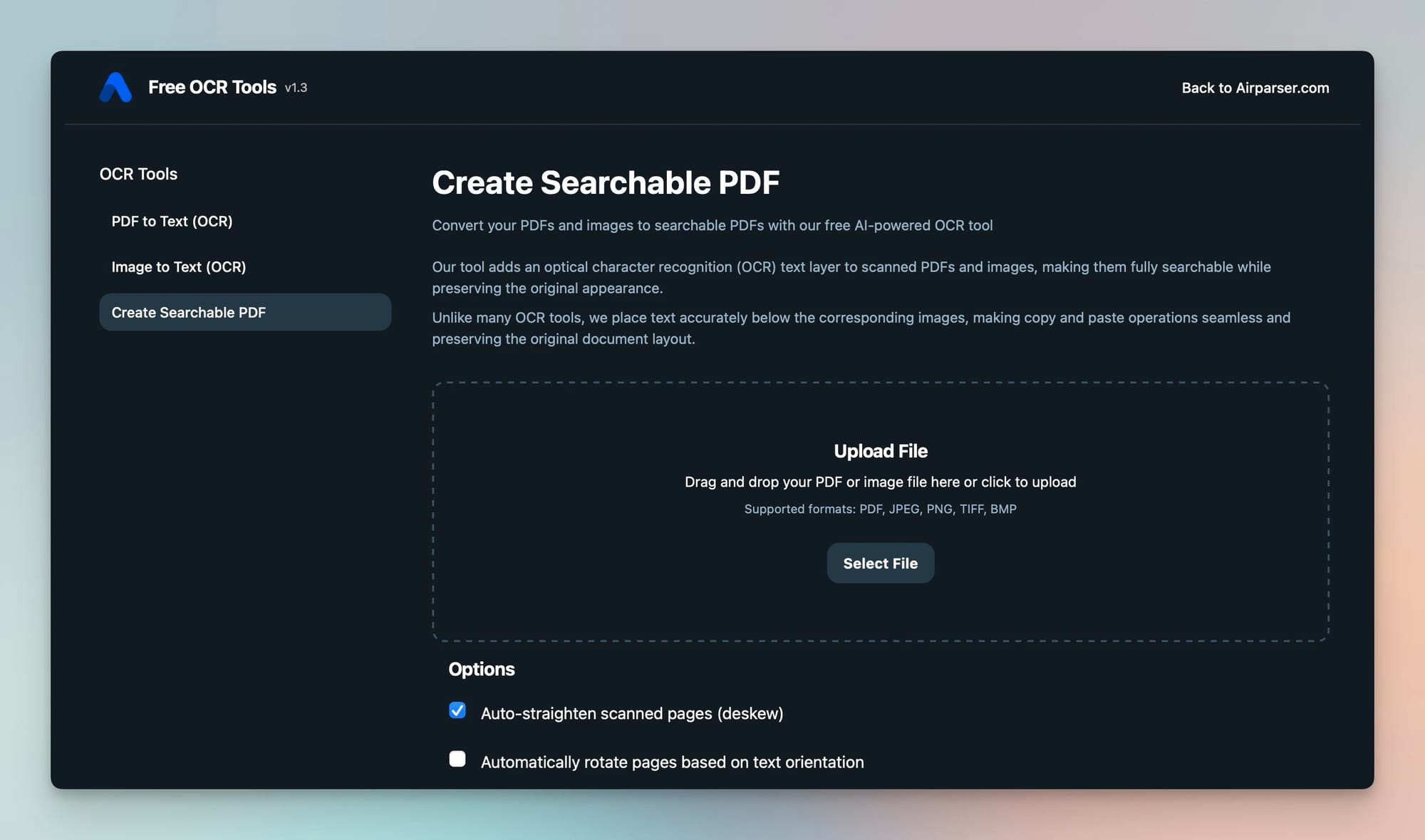
Step 1 — Upload your PDF
Open the OCR tool and upload your document.
Supported formats include:
- JPG
- PNG
- TIFF
- BMP
You can drag and drop your file or click the upload button.
Insert screenshot here
The tool will automatically prepare the document for OCR processing.
Step 2 — Run OCR
Once the file is uploaded, the OCR engine starts detecting text in the document.
The system analyzes:
- letters
- numbers
- punctuation
- document layout
OCR models are trained to recognize text in many fonts and languages.
The tool also includes helpful options such as:
- Auto-straighten scanned pages (deskew)
- Automatic page rotation based on text orientation
These features improve OCR accuracy when documents are scanned at an angle.
Step 3 — Download the searchable PDF
After processing is complete, you can download the new file.
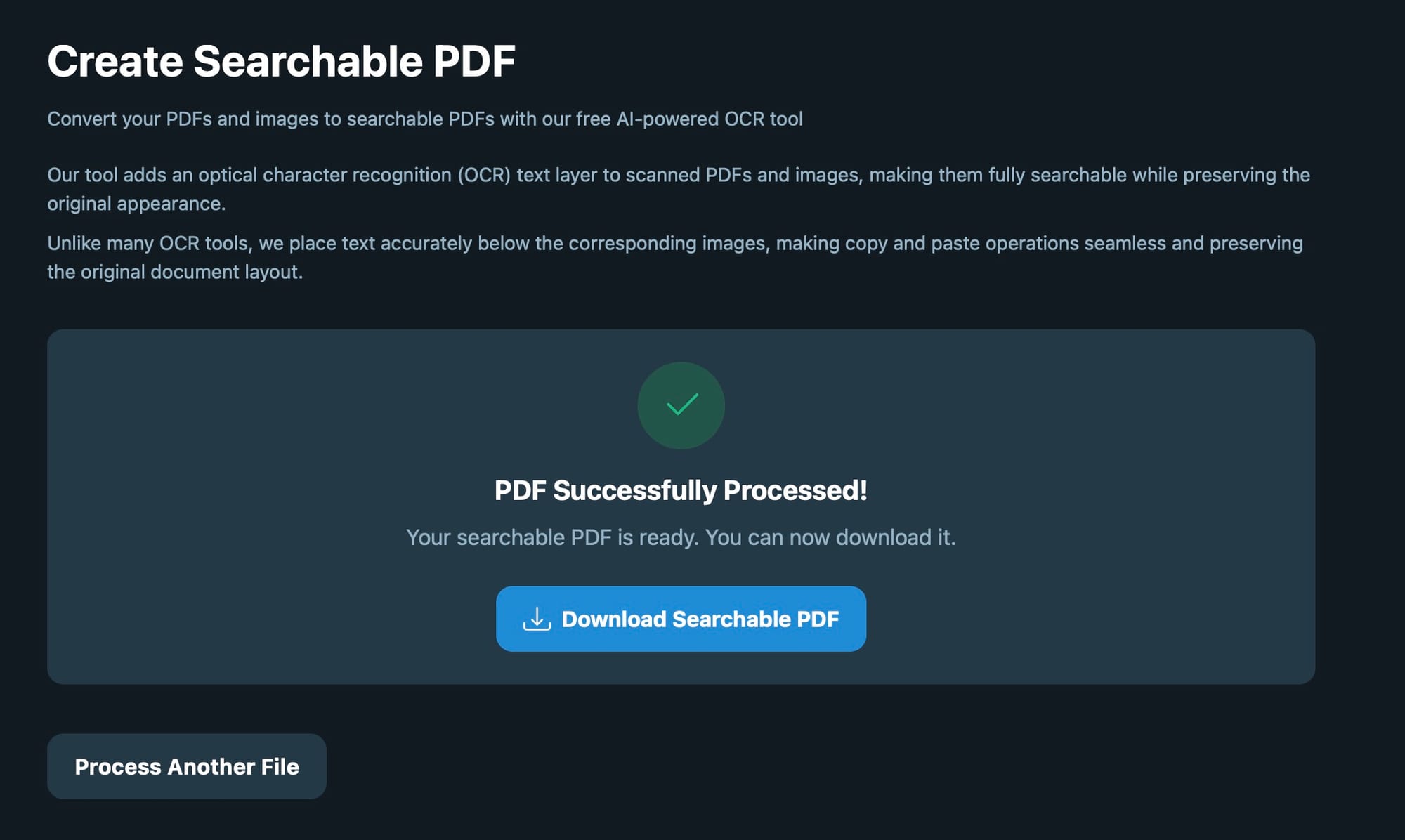
The resulting document contains:
- the original scanned image
- a hidden text layer produced by OCR
Now the document behaves like a normal text-based PDF.
You can:
- search for words
- copy text
- highlight content
- index the document in search systems

Common OCR problems (and how to fix them)
OCR works very well in most cases, but document quality still matters.
Below are some common issues that can affect OCR accuracy.
Low-quality scans
Blurry or low-resolution images make it harder for OCR systems to detect characters.
If possible, scan documents at 300 DPI or higher.
Higher resolution images usually produce better OCR results.
Skewed pages
Sometimes scanned pages are slightly tilted.
This can cause OCR engines to misinterpret characters.
Using a deskew option automatically straightens the page before OCR is applied.
Rotated documents
Documents that are scanned upside down or sideways can also affect accuracy.
Automatic page rotation detects the orientation of the text and rotates the page correctly before processing.
Complex layouts
Documents with multiple columns, tables, or unusual layouts may require more advanced processing.
Modern OCR engines analyze layout structure to better understand how text is organized on the page.
When OCR is not enough
OCR is perfect when you want to make a document searchable.
However, many workflows require something more advanced: extracting structured data from documents automatically.
For example, businesses often need to extract information such as:
- invoice numbers
- dates
- totals
- customer names
- email addresses
- order details
OCR alone does not organize this information.
This is where document parsing tools become useful.
Extract data automatically with Airparser
If you need to extract structured data from PDFs, emails, or images automatically, you can use Airparser.
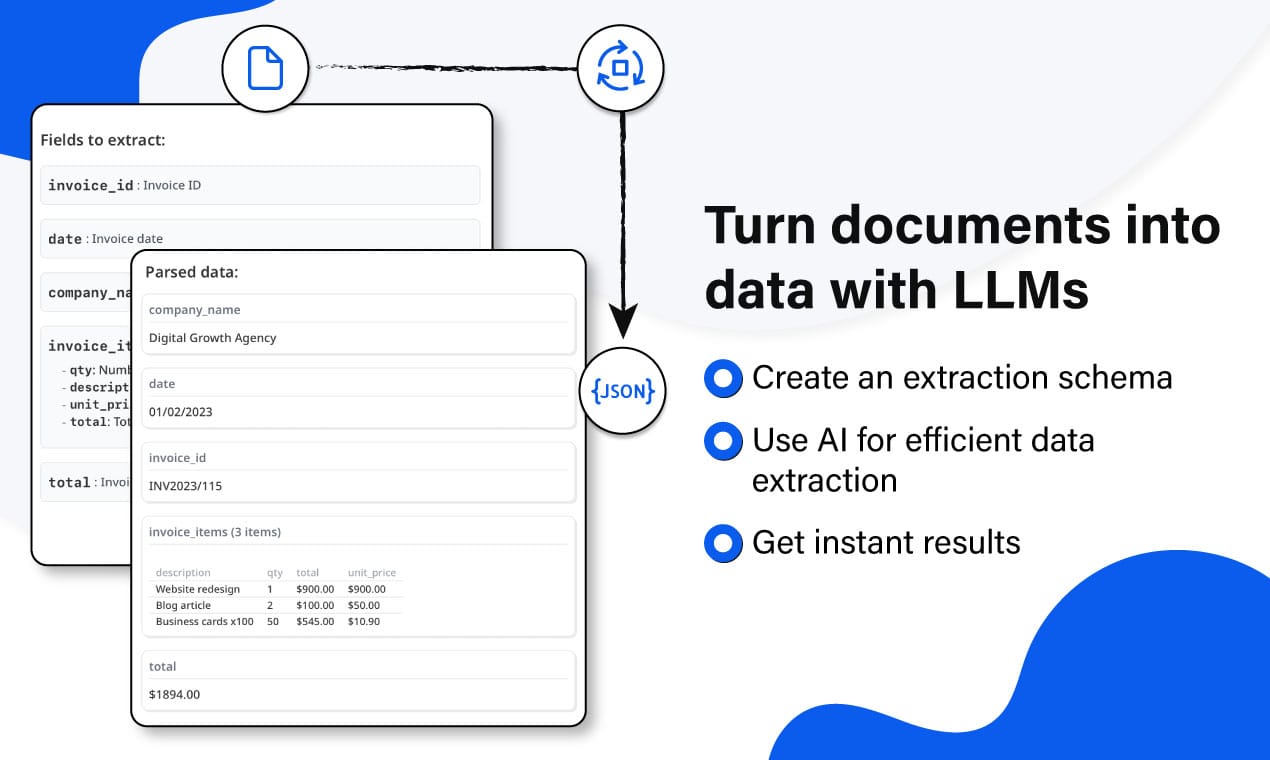
Airparser is an LLM-powered document parser that allows you to define the fields you want to extract from documents.
For example:
- invoice number
- customer name
- total amount
- order ID
- email address
Once the fields are defined, Airparser automatically extracts the data and sends it to other tools such as:
- Google Sheets
- Excel
- APIs
- automation platforms
This allows businesses to automate document-heavy workflows without manual data entry.
Conclusion
Many PDF files are not searchable because they contain images instead of text.
This usually happens when documents are scanned or photographed.
Using OCR, you can convert these files into searchable PDFs that allow you to:
- search text
- copy text
- highlight content
- extract information
You can convert your document using this free tool:
https://ocr.airparser.com/searchable-pdf
If you later need to extract structured data from documents automatically, tools like Airparser can help automate the entire process.
FAQ
What is a searchable PDF?
A searchable PDF contains a hidden text layer behind the document image. This allows you to search, copy, and highlight text even if the original document was scanned.
How do I convert a scanned PDF to a searchable PDF?
You can convert a scanned PDF using OCR (Optical Character Recognition). OCR detects the text in the document image and adds a searchable text layer to the PDF.
You can convert your document using this free tool:
https://ocr.airparser.com/searchable-pdf
Is OCR accurate?
Modern OCR technology is highly accurate for clear documents. Accuracy may depend on scan quality, resolution, and document layout.
Scanning documents at 300 DPI or higher usually produces the best results.
Can I make a PDF searchable for free?
Yes. Many OCR tools allow you to convert scanned documents into searchable PDFs for free.
You can try the free tool here:
https://ocr.airparser.com/searchable-pdf




