Combining LLMs with Traditional OCR for Document Parsing
Learn how combining OCR with LLMs like GPT-4 improves document parsing accuracy. Discover how Airparser enhances data extraction from complex and unstructured documents.


Extracting data from complex documents has always been a challenging task. Traditional Optical Character Recognition (OCR) systems work well for simple text extraction, but they struggle when dealing with unstructured text, diverse layouts, or handwritten notes. This limitation becomes even more apparent when handling complex documents such as legal contracts, financial reports, or multi-page invoices.
The solution? Combining OCR technology with Large Language Models (LLMs) like GPT-4. This hybrid approach enhances parsing accuracy by understanding the context and structure of documents, something OCR systems alone cannot achieve. Tools like Airparser make this integration easy and effective, allowing users to extract structured data from even the most challenging documents.
To understand why this approach works so well, let’s dive into how OCR and LLMs function separately and why combining them is the way forward.
What Is OCR and Its Limitations?
Optical Character Recognition (OCR) is a technology used to convert printed or handwritten text into machine-readable text. Popular OCR tools like Tesseract and ABBYY FineReader work by analyzing the structure of characters, words, and sentences to digitize text from scanned documents or images.
However, while OCR systems are effective at recognizing printed text, they fall short in several areas:
- Lack of Context Understanding: OCR systems can only recognize text without understanding its meaning. For example, they cannot distinguish between a name, an address, or a date unless explicitly programmed to do so.
- Poor Handling of Complex Layouts: Documents with tables, mixed content, or non-standard formats are challenging for OCR to parse accurately.
- Handwritten Text Issues: OCR systems often struggle with handwritten text, especially if the handwriting is messy or inconsistent.
- Inflexibility: OCR systems are generally rule-based, making them less effective when handling documents with varying structures and layouts.
For example, in use cases like Parsing PDFs: Traditional Methods vs. ChatGPT, OCR’s limitations become apparent when comparing it to more advanced AI approaches.
What Are LLMs and How They Improve Parsing?
Large Language Models (LLMs) like GPT-4 represent a significant advancement in AI technology. Unlike OCR, which simply recognizes text, LLMs understand context, meaning, and relationships between different parts of the text.
How LLMs Work
LLMs are trained on vast amounts of text data, allowing them to recognize patterns, comprehend sentences, and extract relevant information even from unstructured documents. They excel at tasks involving:
- Contextual Understanding: Recognizing the meaning of words and sentences in various contexts.
- Natural Language Parsing: Extracting relevant data from complex, unstructured text.
- Handling Diverse Content: Understanding tables, lists, paragraphs, and handwritten notes effectively.
For example, if you want to extract structured data from an unstructured document like an email, LLMs are particularly useful. Tools like Airparser utilize GPT-4 to enhance parsing accuracy and make sense of messy or complex documents.
Compared to traditional OCR systems, LLMs are much better at understanding legal contracts, financial statements, and other documents where context matters. You can read more about how LLMs can be applied in different scenarios in articles like How to Create Document Classification with LLM.
The real magic happens when OCR and LLMs work together. In the next section, we’ll explore why this combination is so effective and how you can use Airparser to enhance your document parsing capabilities.
Why Combining OCR and LLMs Works Better
When you combine OCR and LLMs, you leverage the strengths of both technologies. OCR excels at recognizing and extracting text from scanned documents and images. Meanwhile, LLMs like GPT-4 interpret and structure that text based on context and meaning.
Benefits of Hybrid Parsing
- Improved Accuracy: By combining OCR’s ability to read text with LLM’s understanding of context, you can achieve higher accuracy in data extraction. This is especially useful for documents with mixed formats, such as tables, paragraphs, and handwritten notes.
- Handling Complex Documents: Hybrid parsing is ideal for documents with irregular layouts or where standard OCR alone would struggle. For example, legal contracts often have varying structures that LLMs can better understand.
- Scalable and Adaptable: This approach is highly adaptable, allowing you to process documents from various industries such as finance, healthcare, and logistics. Learn more about its application in AI-Powered Data Extraction for Supply Chain and Procurement Documents.
Using a tool like Airparser, you can seamlessly combine OCR and LLMs to enhance parsing accuracy, even when dealing with challenging documents.
How to Use Airparser for Hybrid Parsing
Using Airparser to combine OCR and LLMs is straightforward. Here’s how to do it:
Step 1: Upload Your Document
Create an inbox and import your first document: send an email to a special address or simply upload your document. This could be a PDF, email, image, or even scanned handwritten notes.
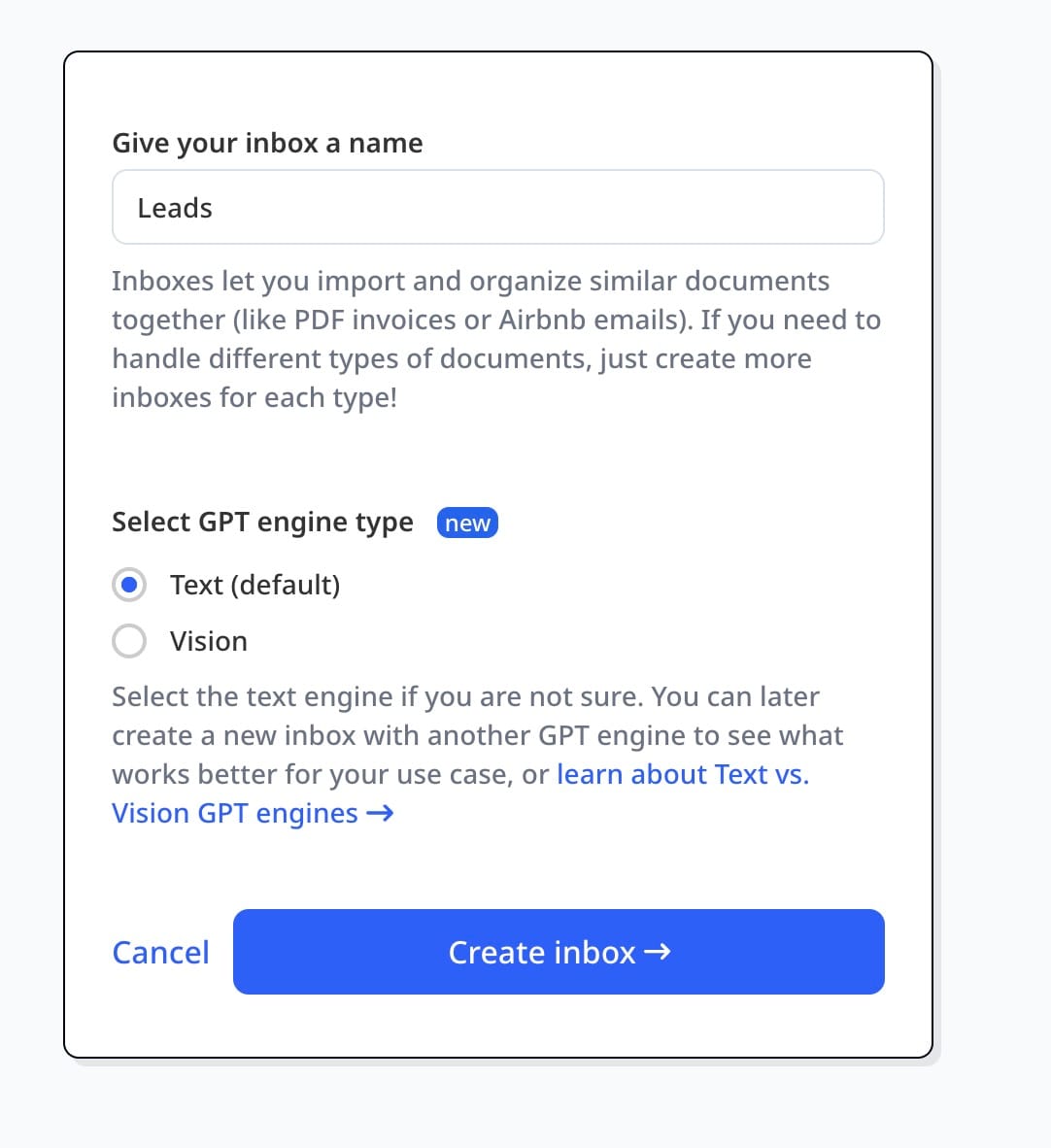
Step 2: Create an Extraction Schema
Define what information you want to extract. With Airparser, you can easily create schemas specifying fields such as names, dates, addresses, tables, or any other data points you need.
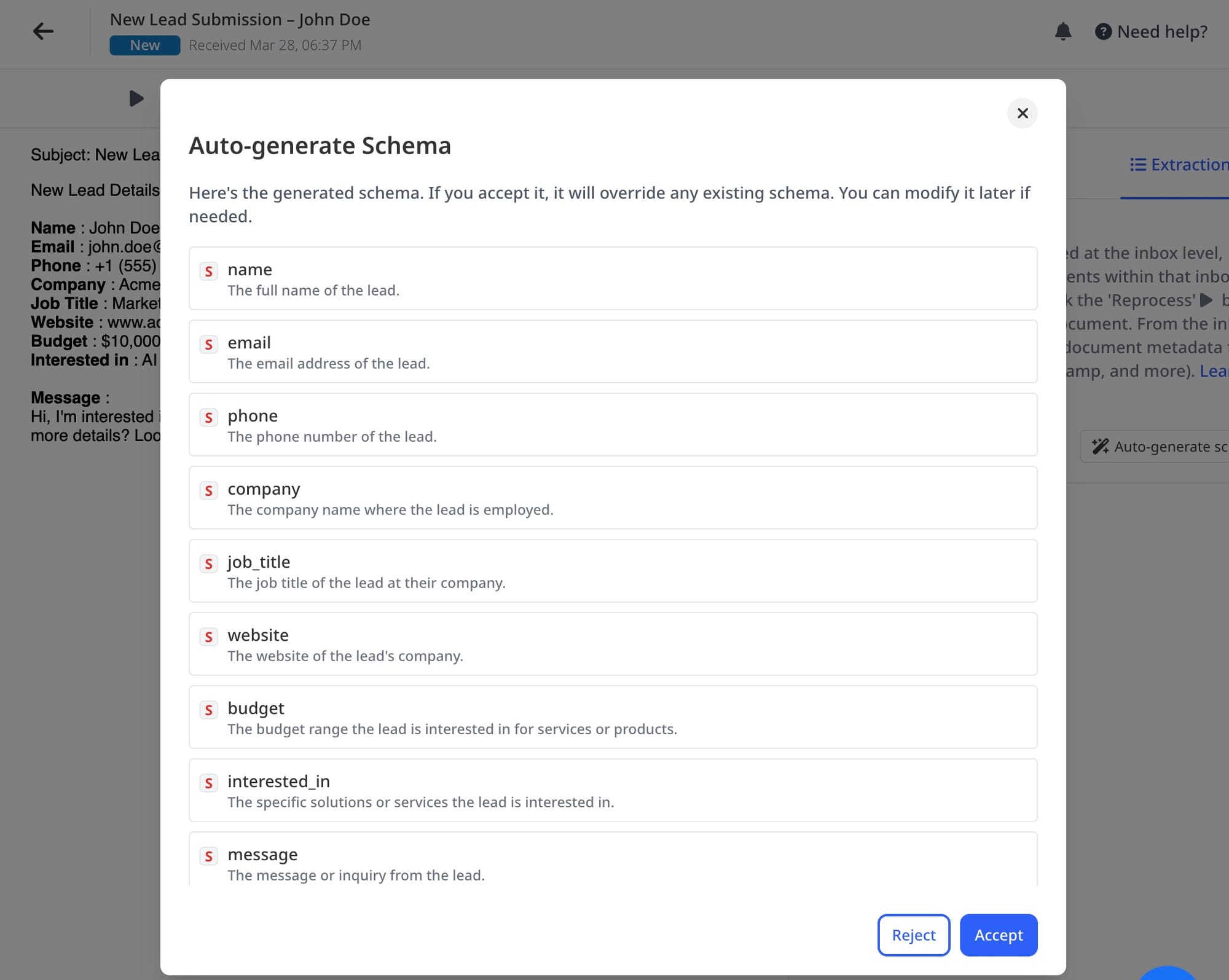
Airparser can also create an extraction schema automatically for you by analyzing a sample document and determining the most important data points.
Step 3: Run the Parsing Process
Click the “Parse” button to start the extraction process. For text-based documents, Airparser can analyze them directly, and it uses OCR for images and scanned documents.
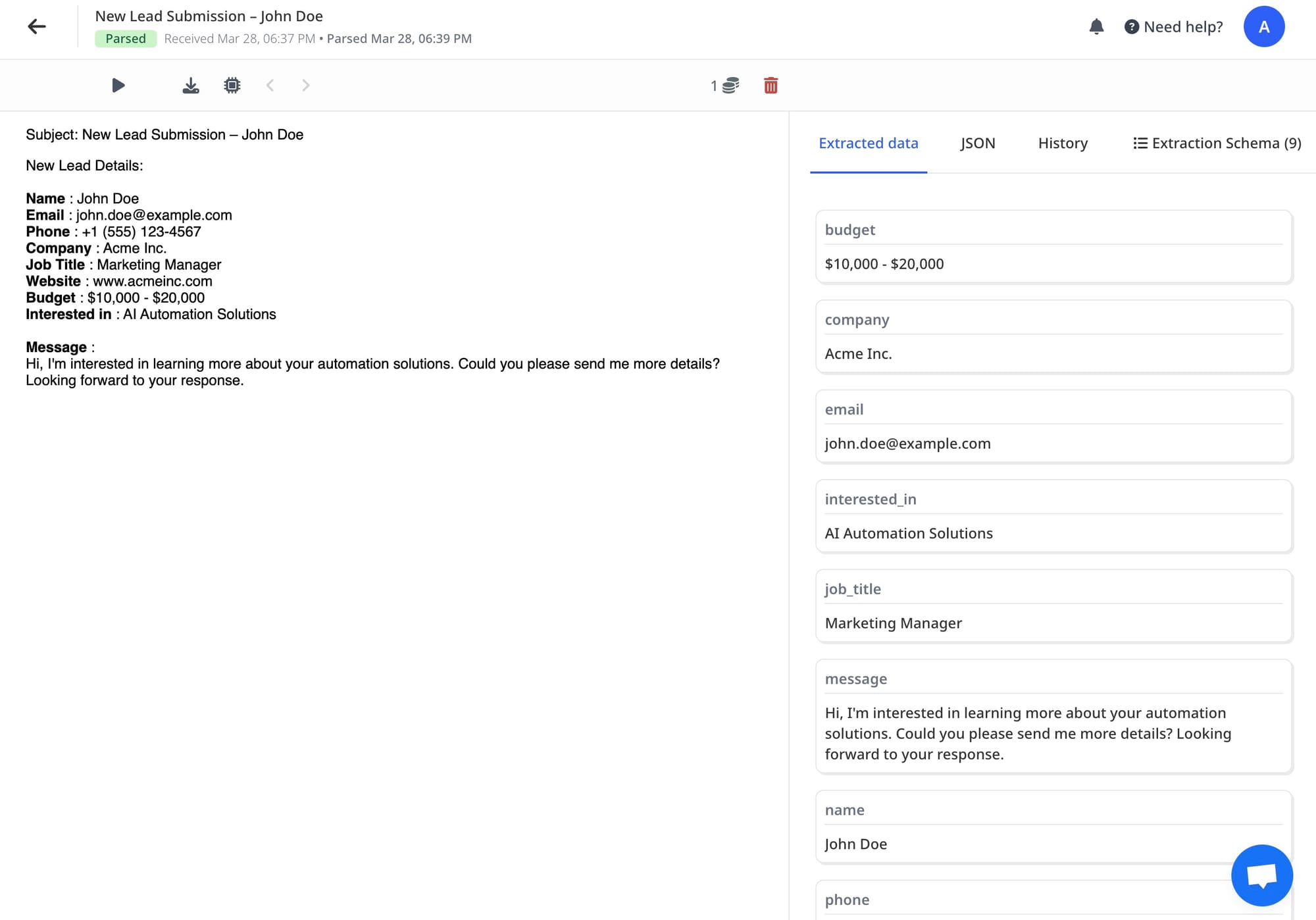
Step 4: Review and Export Results
Once parsing is complete, review the extracted data. You can then download it in your preferred format, such as JSON, CSV, or Excel.
From now on, all incoming documents into the same inbox will be parsed using the defined extraction schema.
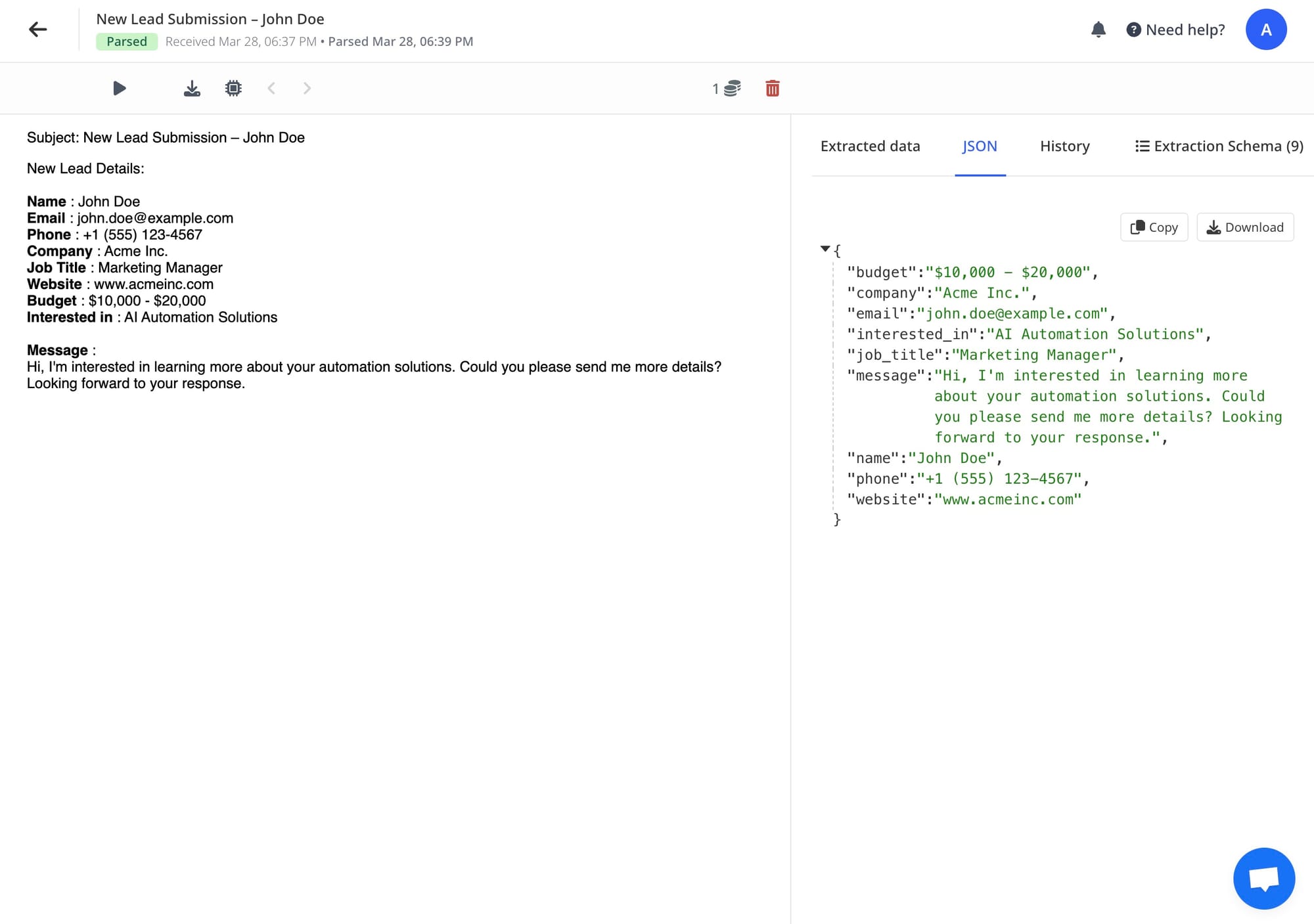
You can create integrations and automatically export the extracted data to virtually any platform—Google Sheets, CRM, accounting software, and more.
Real-World Applications
Hybrid parsing is highly effective across various industries:
- Legal: Parsing contracts, agreements, and case files with varying structures.
- Finance: Extracting data from reports, invoices, and financial statements.
- Healthcare: Analyzing medical documents, patient records, and insurance forms.
- Logistics: Processing shipment documents, packing lists, and invoices.
Airparser makes it easy to tackle these complex tasks by combining OCR and LLMs effectively.
Conclusion
Combining OCR with LLMs offers a powerful approach to document parsing. With Airparser, you can handle complex, unstructured, and messy documents with improved accuracy and efficiency. Try it for your own document parsing needs and see the difference.




