Comparing AI Extraction Methods: Traditional OCR vs. LLM Parsing
Learn the differences between OCR and LLM parsing, and how to extract data from documents easily using Airparser’s AI-powered tool.


Extracting data from documents saves time and prevents mistakes. It helps individuals and businesses keep accurate records. But how do you get data from a PDF or scanned file into a spreadsheet automatically?
There are two main ways to turn documents into structured data. One is traditional OCR (Optical Character Recognition). The other is LLM parsing, which uses large language models. In this article, you’ll learn the differences between them. You’ll also see how to use Airparser’s LLM-powered parsing to extract data from any document without writing rules or templates.
For related topics, check out How to Extract Data from Scanned Handwritten Forms Using AI and Combining LLMs with Traditional OCR for Document Parsing.
What Is Traditional OCR?
Traditional OCR stands for Optical Character Recognition. OCR scans a document image, finds the letters and numbers, and converts them into text.
OCR has been used for decades to digitize printed papers. It is very useful when you have clear scans or printed documents with a fixed format. Examples of OCR use cases include:
- Scanned invoices
- Printed contracts
- Typed receipts
OCR works well when the document layout does not change. It is fast and cheap. But it has limits. If the document’s structure varies or has complex elements like tables or lists, OCR can miss data or capture it incorrectly.
What Is LLM Parsing?
LLM parsing uses large language models to read and understand documents. Unlike OCR, which only finds letters, LLM parsing understands meaning and context.
For example, a large language model can find the total amount due on an invoice, even if the layout changes between documents. LLM parsing can also handle unstructured text, such as emails or letters, where data does not follow a fixed format.
LLM parsing works well for:
- Invoices with different layouts
- Contracts with multiple sections
- Emails with important information
- Complex documents mixing text, tables, or lists
Airparser uses LLM parsing to extract data from PDFs, emails, images, or other documents. It does not require any templates or complex rules. You just list the fields you want, and Airparser’s AI engine understands the document and extracts the data.
For more on document classification and extraction, see How to Create Document Classification with LLM and How to Extract Structured Data from Emails and PDFs.
Comparing Accuracy and Flexibility
Traditional OCR works best with fixed layouts. For example, a utility bill from the same provider will always have the same columns and rows. OCR can quickly process these. But if the format changes, OCR struggles.
LLM parsing is better for documents where the layout can change. For example, if invoices from different vendors have unique designs, LLM parsing adapts automatically.
Examples:
- Use OCR for printed forms that never change.
- Use LLM parsing for receipts or contracts from many vendors with different formats.
In How to Use AI to Parse Utility Bills and Extract Structured Data, you can see how LLM parsing helps extract billing details even if the provider updates the bill’s design.
Speed and Resource Requirements
OCR is often faster because it only detects and copies letters. It doesn’t need to understand context. If you need to process thousands of pages quickly and the documents are similar, OCR is a good option.
LLM parsing takes longer. It reads the text and tries to understand meaning, relationships between fields, and different sections. But the extra time means better accuracy for complex or unstructured documents.
Costs and Maintenance
OCR tools are cheaper to run at scale. They don’t use much computing power. But they require maintenance if your document layouts change. You have to update templates or zones often.
LLM parsing costs more because it uses advanced AI models. But you save time because you don’t need to maintain templates. Airparser’s LLM parser adapts to each document’s structure, so you don’t worry about manual updates.
How to Extract Data from Documents with Airparser
Airparser uses LLM parsing for all documents. Here’s how to set up Airparser to extract data easily:
Step 1: Create an Inbox
Log in to your Airparser account and create a new inbox. Each inbox has a unique email address where you can send or forward documents. You can also upload files manually or use Zapier or Make for automation.
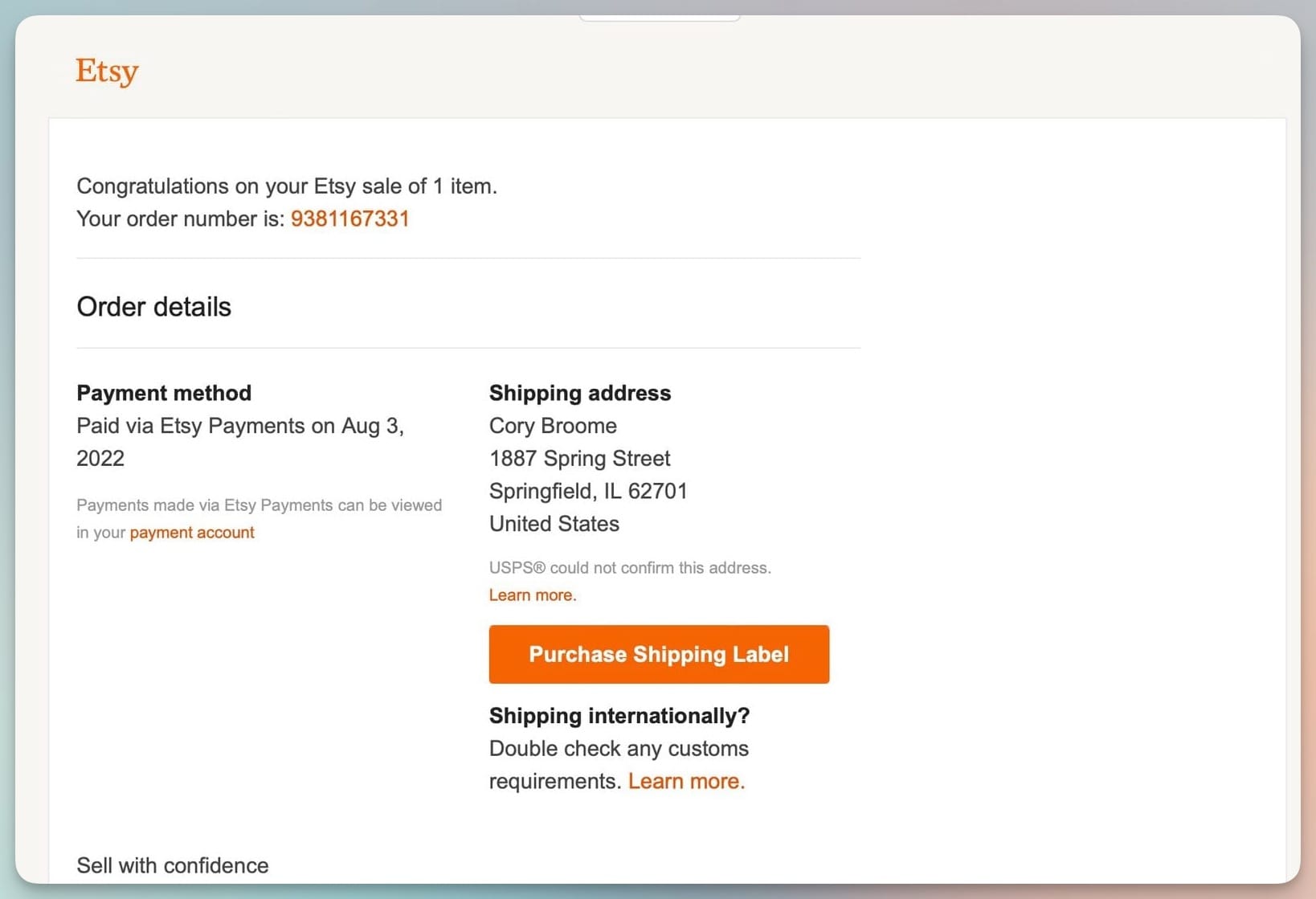
Step 2: Upload a Sample Document
Send your first document — for example, a PDF invoice or order confirmation. You can upload it directly or forward it to your inbox’s email address.
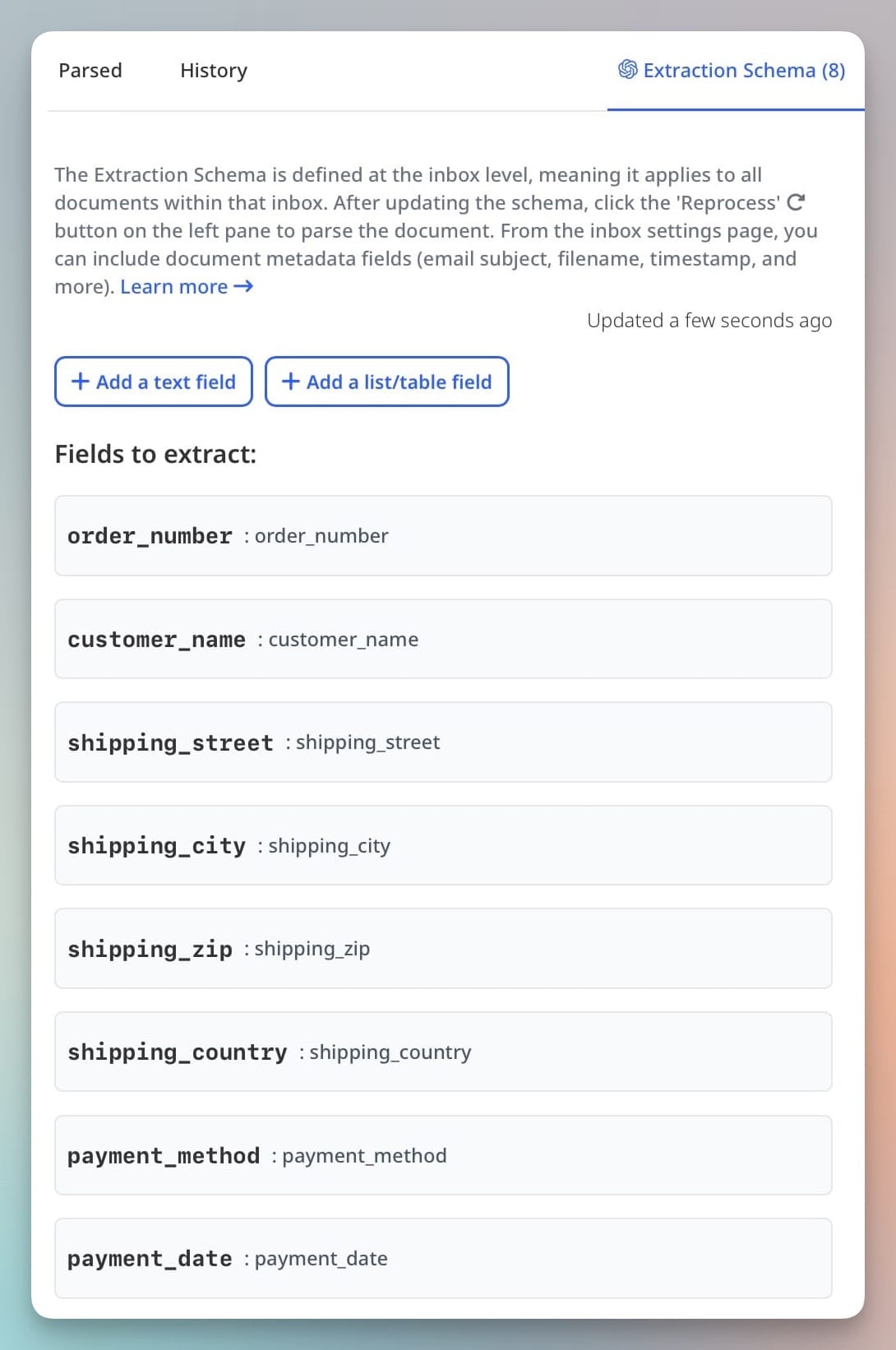
Step 3: Create an Extraction Schema
Once the document is uploaded, Airparser shows a preview. You then list the fields you want to extract, like:
- Invoice Number
- Vendor Name
- Amount
- Due Date
Airparser’s LLM-powered engine reads the document and extracts these fields automatically. There’s no need to create templates or zones.
In How to Export PDFs to Google Sheets Automatically, you can see a complete guide on extracting data with Airparser and sending it to Google Sheets.
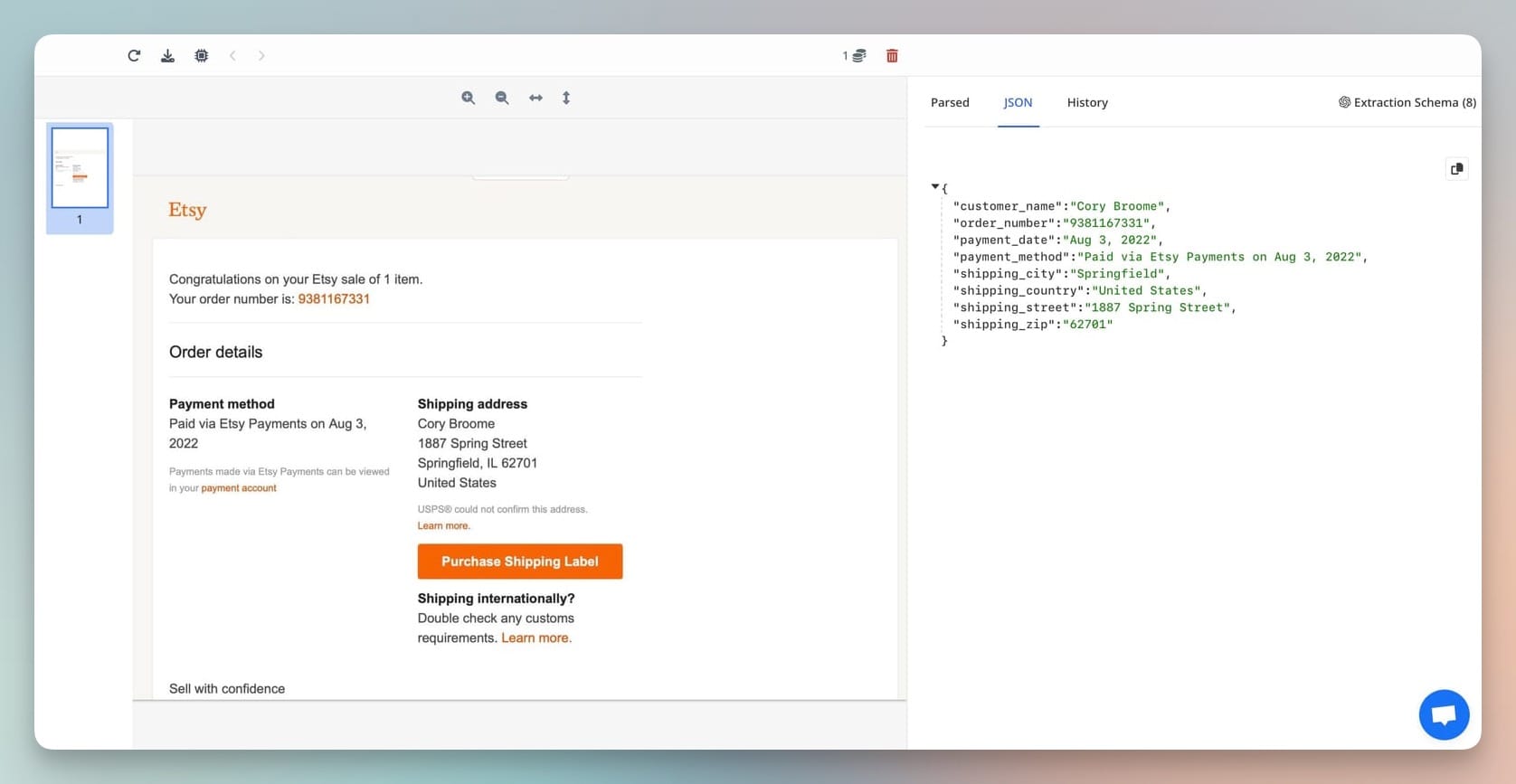
Step 4: Review and Fine-Tune
Check the extraction preview. Make sure the data is accurate. If needed, add or remove fields in your extraction schema.
Step 5: Automate Your Workflow
When you are happy with the results, connect your inbox to other tools:
- Google Sheets
- QuickBooks
- Your database
Each new document sent to your inbox will be parsed automatically. The extracted data will go directly to your chosen tools.
For another example, see How to Automate Subscription Invoice Parsing for SaaS Companies.
Best Practices for Reliable Data Extraction
- Use high-quality scans or original PDFs for better accuracy.
- Test a few sample documents before automating your workflow.
- If you handle documents with both fixed and variable layouts, remember Airparser’s LLM parser adapts automatically.
For more on automating data extraction, check Expense Management with AI-Powered Data Extraction.
Conclusion
Traditional OCR and LLM parsing are two different methods for extracting data from documents. OCR is great for fixed, printed layouts. But it struggles with changing formats.
LLM parsing, like the one Airparser uses, can understand unstructured documents and extract data even when layouts vary. This makes it the better choice for most modern workflows.
With Airparser, you don’t need to choose between methods or create templates. Just list the fields you want, and the LLM parser does the work. This saves time, reduces errors, and helps you keep accurate records.
For more step-by-step guides, visit Airparser’s blog.




