LLM APIs vs. Airparser for Invoice Parsing: An Honest Comparison
GPT, Claude, and Gemini can all parse invoices. The question is whether a raw LLM API is the right tool for a production pipeline. Covers accuracy, hidden engineering effort, and when each approach makes sense.

TL;DR:
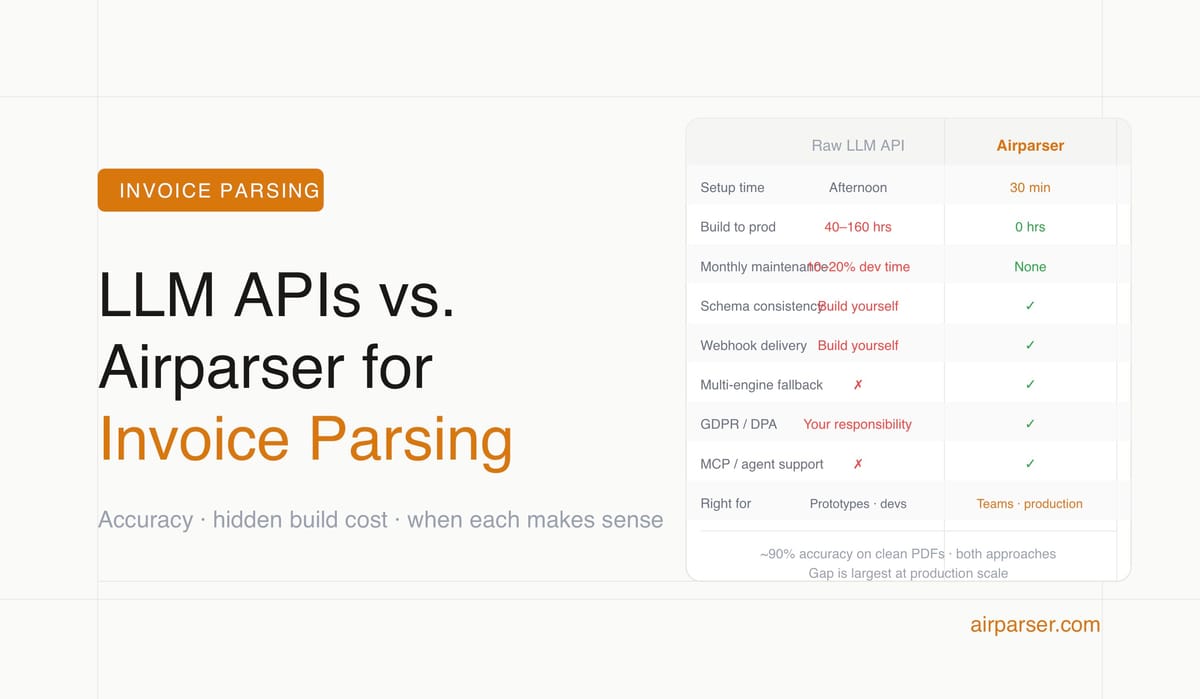
- Frontier LLMs (GPT, Claude, Gemini) achieve ~90% field accuracy on clean, standard invoices — good enough for prototypes and one-off jobs.
- Production pipelines built on raw LLM APIs require 40–160 hours of engineering to build validation, error handling, retry logic, and webhook delivery — before a line of business logic is written.
- Ongoing maintenance of a custom LLM extraction pipeline adds 10–20% of a developer's monthly time — cost that doesn't appear in the API token bill.
- Airparser handles extraction, schema enforcement, webhook delivery, multi-engine fallback, and GDPR compliance out of the box — the right tradeoff for teams who need reliable output without building infrastructure.
Frontier LLMs — GPT, Claude, Gemini — can parse invoices. At roughly 90% field-level accuracy on clean, standard PDF invoices, a direct API call with a vision-enabled model returns recognizable structured data in seconds. Every developer who has tried this knows it works. The honest question is not "can it extract invoice fields?" — it's "what does a production pipeline built on a raw LLM API actually look like, and what is its true all-in cost?"
This comparison is written for teams who have already had the LLM prototype moment — tried GPT, Claude, or Gemini on a few invoices, got impressive results — and are now deciding whether to build a production pipeline around a raw LLM API or use a dedicated extraction service like Airparser. Both approaches are legitimate. The right choice depends on your team's technical capacity, document volume, tolerance for maintenance overhead, and compliance requirements.
We'll cover what LLMs genuinely do well for invoice extraction, where they break down at production scale, the real engineering cost, and a clear decision framework for each use case.
What LLMs Get Right on Invoice Extraction
The multimodal vision capability of frontier LLMs is genuinely impressive for invoice parsing. Upload a PDF or image of an invoice, ask for specific fields in JSON format, and you get back recognizable structured data — vendor name, invoice number, due date, totals, line items — with no template configuration or zone mapping required. For clean, digitally-generated PDFs from a single supplier, accuracy from models like GPT, Claude, and Gemini regularly exceeds 95% on standard fields.
The practical strengths are real:
- Zero setup for new document layouts. A frontier LLM handles any invoice format without prior configuration. A new supplier format that would require building a new template in a legacy tool is handled by the same prompt.
- Strong at semantic understanding. It knows that "€1,234.00" near the word "Total" at the bottom of an invoice is the invoice total, not a line-item amount. This contextual understanding outperforms zonal OCR on variable-layout documents.
- Flexible output structure. You define exactly which fields to extract, in which format, using natural language. The schema is the prompt.
- Low token cost at small volumes. Raw API token cost for invoice extraction is low — a few cents per document at typical input sizes. For low-volume one-off jobs the economics are attractive.
These are real advantages. A developer can build a working invoice parser in an afternoon using GPT, Claude, or Gemini — and for an internal tool, a prototype, or a one-time data migration, that is genuinely the right approach.
Where Raw LLM Parsing Breaks Down in Production
The prototype-to-production gap is real, and it is larger for LLM-based invoice parsing than most teams expect. The following failure modes are not theoretical — they are patterns that consistently emerge when teams move a custom LLM invoice parser from internal testing to production.
Hallucination on financial figures
LLMs — whether GPT, Claude, or Gemini — can invent figures that aren't in the document: transposing numbers, confabulating a total that mathematically "makes sense" based on the visible line items, or filling a missing field with a plausible-looking value. For financial documents, a hallucinated invoice total or transposed amount is not a minor annoyance — it can enter accounting records as real data. The hallucination rate is low on clean, well-formatted invoices, but non-zero. Over thousands of invoices per month, even a 0.5% hallucination rate produces hundreds of bad records.
Inconsistency across near-identical documents
An LLM may extract a field correctly from one invoice and differently from a nearly identical invoice from the same supplier. Field names can shift subtly between runs ("invoice_no" vs "invoice_number"), date formats can vary ("05/17/2026" vs "2026-05-17"), and currency strings may or may not include symbols. Downstream systems — databases, spreadsheets, ERPs — break on these inconsistencies. Making output truly consistent requires extensive prompt engineering, output validation, and format-normalization code.
Structured output reliability in complex cases
OpenAI's Structured Outputs and equivalent features in Claude and Gemini improve schema compliance significantly. But these features have constraints: they don't support all JSON schema features, can fail silently on deeply-nested schemas, and community reports describe reliability issues with complex nested structures. For invoices with multi-level line-item tables, nested discount structures, or non-standard field combinations, structured outputs alone aren't a guarantee of clean, valid JSON every time.
Multi-page invoices and table extraction
Invoices with many line items often span multiple pages. The LLM's context window handles the full document in theory, but vision processing of multi-page PDFs typically requires splitting into per-page images and then reconciling extracted data across pages — a non-trivial engineering problem. Table structures with merged cells, complex column headers, or variable-width layouts consistently produce lower extraction accuracy than single-field extraction.
Scanned and photographed invoices
Many real-world invoice workflows include scanned paper invoices, photographed receipts from expense management, and faxed documents. The quality of extraction degrades significantly with poor scan quality, skewed images, low resolution, or handwritten annotations. Frontier LLMs handle these cases but with meaningfully lower accuracy than digitally-generated PDFs — and without a built-in fallback mechanism.
The Real Cost Comparison
Raw token cost is not the right unit of comparison. The real cost of a production invoice pipeline includes the engineering time to build it, the ongoing maintenance burden, and the cost of errors that make it through to downstream systems.
What building it yourself actually costs
A production-ready invoice parsing pipeline built on a raw LLM API requires:
- Webhook receiver — a server that accepts incoming invoices from email, upload, or storage triggers and queues them for processing
- Document preprocessing — PDF-to-image conversion, multi-page splitting, image quality checks, format normalization
- Prompt engineering — designing and iterating a prompt that produces consistent, accurate output across the invoice variants you receive
- Output validation — checking that required fields are present, formats are consistent, and mathematical relationships hold (line items sum to subtotal, subtotal + tax = total)
- Error handling and retry logic — handling API failures, rate limits, malformed JSON responses, and partial extractions
- Schema versioning — managing prompt updates when new supplier invoice formats require extraction changes
- Delivery pipeline — writing validated results to your database, spreadsheet, or downstream system
- Monitoring and alerting — detecting when extraction quality degrades, when new invoice formats cause failures, or when the API has an outage
Conservative estimates for this build: 40–80 hours for an initial working version, 80–160 hours for a production-hardened pipeline. At market rates for a mid-level developer ($100–$150/hour), that's $4,000–$24,000 in one-time build cost. Ongoing maintenance — prompt tuning as new invoice variants arrive, handling API changes, monitoring — adds 10–20% of a developer's monthly time: $1,500–$4,500/month at market rates.
Airparser's subscription covers schema definition, multi-engine extraction (text LLM + vision LLM), webhook delivery, error handling, GDPR-compliant data processing, configurable data retention, and monitoring — with no build time and no ongoing maintenance cost. The question is not whether the raw LLM token cost is higher or lower than Airparser's subscription; token cost is typically low. The real comparison is whether your team's engineering time — the hours to build, maintain, monitor, and update the extraction pipeline — is worth more than the subscription fee. For most non-engineering teams, the answer is yes at almost any volume.
What Airparser Does Differently
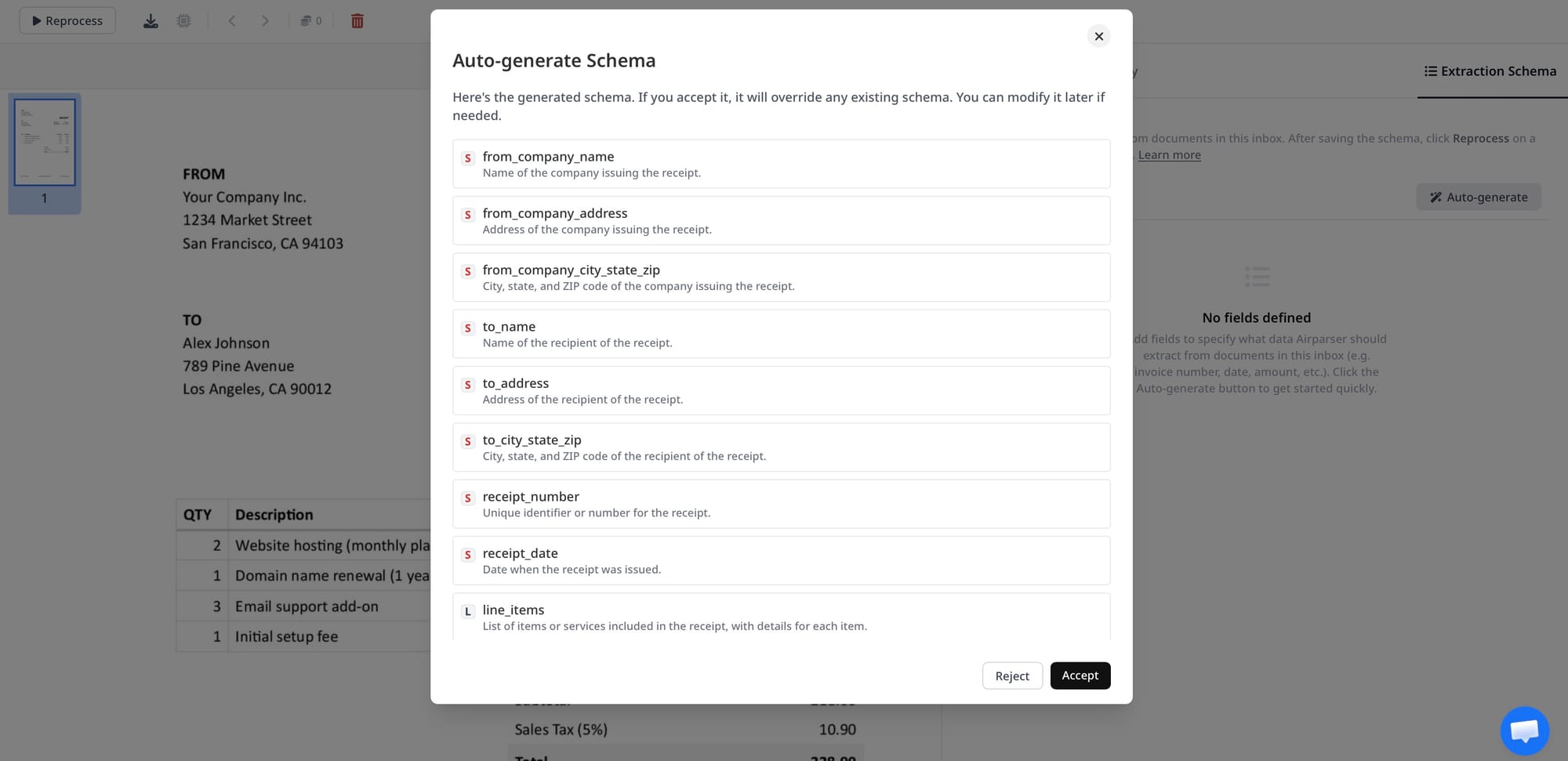
Airparser is not simply "an LLM with a UI." The platform wraps several capabilities that take significant engineering effort to replicate:
Multi-engine fallback. Airparser automatically routes documents between text LLM extraction, vision LLM extraction, and OCR based on document type and quality. A scanned invoice that would confuse a vision-only approach gets the best engine for that specific input — without any configuration on your part.
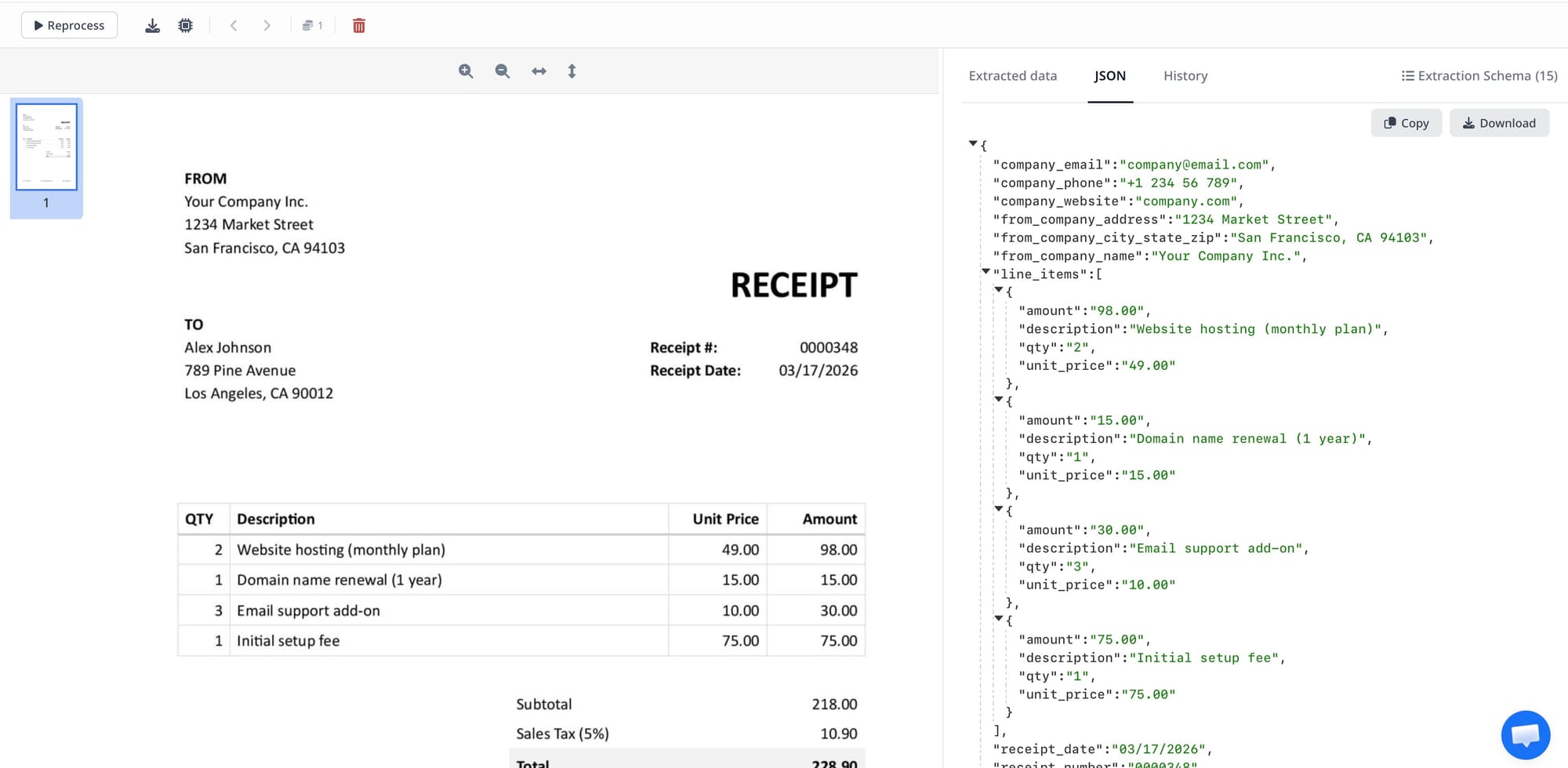
Schema enforcement across runs. Your defined schema is applied consistently to every document. Field names, data types, and formats don't vary between extractions. The same invoice from the same supplier processed twice produces structurally identical JSON.
Email inbox as a first-class ingestion channel. Airparser gives each parser a dedicated email address. Your team or suppliers send documents directly to that address; Airparser processes attachments automatically. No file upload interface, no webhook receiver to build, no document routing logic to write.
Webhook delivery is built in. Configure a delivery URL and Airparser POSTs extraction results immediately on completion. No server to host, no polling loop to write, no delivery pipeline to build.
Native integrations. Zapier, Make, n8n, and Google Sheets are all native integrations — no custom code needed for most common downstream destinations.
GDPR compliance out of the box. AES-256 encryption, configurable data retention, a Data Processing Agreement, and a no-model-training policy are all in place. Building equivalent compliance infrastructure on a raw API is non-trivial.
For teams without dedicated engineering resources — finance teams, operations teams, accounting firms automating AP workflows — these capabilities are the reason a subscription is worthwhile. The alternative is not "use a raw LLM API instead of Airparser." The alternative is "hire a developer to build and maintain all of this."
When a Direct LLM API Is the Right Choice
A direct LLM API (GPT, Claude, or Gemini) is the right choice in specific circumstances:
- One-time data migration. Extracting data from 5,000 historical invoices to populate a new database is a one-off job. Build a script, run it, discard it. No production reliability required.
- Internal developer tools with a small, controlled document set. If your team processes 20–30 invoices per week from a handful of known suppliers, a developer can build and maintain a lightweight pipeline with acceptable overhead.
- When the extraction is part of a larger AI pipeline you're already building. If you're building a custom LLM application with agents, RAG, or custom business logic, integrating LLM extraction natively using the same model may be more coherent than adding a separate service.
- When you need extraction logic that Airparser's schema model doesn't support. Complex multi-step reasoning ("sum all line items with category 'consulting', convert to USD at today's rate, flag if total exceeds $10,000") is better expressed in application code against an LLM than configured in a parsing schema.
- Early-stage prototyping. Before committing to any approach, a quick LLM prototype tells you whether automated extraction is feasible at all for your document set.
When Airparser Is the Right Choice
Airparser is the right choice when:
- You need a production pipeline without engineering overhead. Operations teams, finance departments, and non-technical users who need invoice automation running reliably today — not after a 6-week build — are the core Airparser use case.
- You receive invoices from multiple suppliers with variable layouts. Zero template setup means adding a new supplier format costs nothing. A custom LLM pipeline requires prompt testing and validation for each new format variant that causes extraction errors.
- Your documents include scanned PDFs, photographed invoices, or handwritten content. Airparser's vision engine and multi-engine fallback are purpose-built for degraded input quality. A raw vision API call with no fallback will fail silently on these.
- Compliance matters. If your invoices contain personal data under GDPR (which supplier invoices often do), or you're in a regulated industry with data retention requirements, Airparser's built-in compliance infrastructure is significant. Building equivalent controls on a raw API involves legal agreements, infrastructure changes, and ongoing audit work.
- You want to integrate with Zapier, Make, or n8n without writing code. The native integrations cover the most common downstream destinations — Google Sheets, Airtable, webhooks, databases — without API code.
- You want to use Airparser as a tool in an AI agent workflow. Airparser's MCP server lets AI agents (Claude, other MCP-compatible frameworks) call the parser directly as a native tool — the only no-code document parser with this capability as of 2026. Related: Agentic document extraction: what it means and how to build it.
If you want to start with Airparser for invoice parsing, the workflow is: create an inbox, select the engine (text for digital PDFs, vision for scanned documents), upload a sample invoice, review the auto-generated schema, adjust field definitions if needed, then configure delivery to your downstream system. Most teams have their first invoices processing within 30 minutes. See also: How to extract invoice line items from PDFs automatically.
The Same Tradeoffs Apply Beyond Invoices
This comparison uses invoices as the primary example because they're the most common document automation use case — but the build-vs-maintain calculus is identical for other document types.
Contracts. An LLM prototype that extracts party names, key dates, and clause summaries from a contract works well in an afternoon. A production pipeline that handles variable contract structures, multi-party agreements, exhibits and schedules across dozens of pages, and consistent field output across thousands of documents faces the same hallucination, schema consistency, and maintenance challenges described above — amplified by higher document complexity.
Receipts and expense documents. Receipt parsing looks simpler than invoices but introduces its own edge cases: photographed receipts with poor lighting, partial occlusion, handwritten totals, and mixed currencies across an international expense report. A raw LLM call works on clean receipts; the fallback and normalization engineering for real-world expense workflows is substantial.
Resumes and CVs. Candidate documents arrive in hundreds of formats — Word, PDF, scanned, multi-column, creatively designed. An LLM extracts skills, experience, and education well on straightforward resumes. Consistent structured output across a high-volume applicant pipeline — same field names, normalized date formats, skills as arrays rather than prose — requires the same schema enforcement and validation infrastructure that makes invoice pipelines hard to maintain. Related: Resume parsing in the age of LLMs.
The domain changes. The infrastructure problem doesn't. Wherever you're extracting structured data from variable documents at scale, the decision between a raw LLM API and a dedicated extraction service comes down to the same factors: engineering capacity, document volume, consistency requirements, and compliance obligations.
Frequently Asked Questions
Are LLMs more accurate than Airparser for invoice extraction?
On clean, digitally-generated PDF invoices from known suppliers, frontier LLMs (GPT, Claude, Gemini) achieve approximately 90–95% field-level accuracy in direct vision API calls. Airparser's accuracy depends on the engine selected and document type — the vision engine handles scanned and photographed documents that direct LLM vision API calls struggle with, and multi-engine fallback reduces failure rates on edge-case documents. The more meaningful comparison is not raw accuracy on clean documents (both are competitive) but accuracy-at-scale across a real document population that includes variable quality, multi-page invoices, non-standard formats, and scanned documents. For mixed real-world document sets, Airparser's fallback mechanisms and purpose-built schema enforcement produce more consistent output than a raw LLM API call. For a single-supplier, digitally-generated invoice with a consistent format, frontier LLMs and Airparser are comparable in accuracy.
What does it actually take to build a production invoice parser with an LLM API?
A working prototype takes an afternoon — a Python script that reads a PDF, encodes it as base64, calls GPT, Claude, or Gemini with a vision prompt, and parses the JSON response. A production pipeline takes significantly longer. Production requirements that a prototype doesn't address include: a webhook receiver or batch ingestion mechanism to handle documents as they arrive; PDF-to-image preprocessing for multi-page documents; output validation to catch missing fields, wrong formats, and financial inconsistencies (does the extracted total match the sum of line items?); retry logic for API failures, rate limit errors, and malformed responses; a delivery mechanism to write results to your database, spreadsheet, or ERP; monitoring and alerting for extraction quality degradation; and schema versioning as your document set evolves. A realistic estimate for a production-grade pipeline is 40–160 engineering hours for initial build, plus 10–20% of a developer's ongoing time for maintenance. That overhead doesn't go away — it's the cost of owning the extraction infrastructure.
Can LLMs handle scanned and photographed invoices?
Frontier LLM vision capabilities handle scanned and photographed invoices, but with meaningfully lower accuracy than digitally-generated PDFs. Poor scan quality, skewed images, low resolution, handwritten annotations, and faxed documents all degrade extraction accuracy significantly. The practical issue for production workflows is that you don't always control the input quality — suppliers send what they have. A raw LLM API call has no fallback when scan quality is insufficient; it either returns a degraded extraction or errors. Airparser's vision engine is purpose-built for lower-quality inputs and includes multi-engine fallback — if one extraction approach produces a low-confidence result, the system tries alternative approaches. For workflows where you receive invoices from many different suppliers with varying scan quality, the fallback handling meaningfully reduces the rate of failed or inaccurate extractions.
How do LLMs and Airparser compare on multi-page invoices with complex line-item tables?
Multi-page invoices with complex tables are a known weak point for direct LLM vision API calls. Each page typically must be processed as a separate image, which means line items that span a page break need to be reconciled across two extraction calls — a non-trivial engineering problem. Table structures with merged cells, complex column headers, sub-totals within the table, and variable column widths produce lower accuracy than simple single-page invoices. Airparser's extraction engine is designed for document-level understanding rather than per-page image processing, which handles multi-page continuity more naturally. For organizations processing invoices from enterprise suppliers with 5–20 page purchase order sets or freight invoices with complex tabular structures, testing both approaches against your specific document set is essential before committing to a pipeline. The gap between approaches is largest on complex real-world documents and smallest on simple, clean, single-page invoices. Related: How to extract invoice line items from PDFs automatically.
What are the GDPR implications of using an LLM API to process invoices with personal data?
Supplier invoices frequently contain personal data under GDPR: the name and contact details of the person who issued the invoice, registered business addresses that may correspond to residential addresses for sole traders, banking details in some invoices, and customer reference data. Sending this data to a third-party LLM API means processing it under that provider's data processing terms. OpenAI, Anthropic, and Google all offer Data Processing Agreements for API customers, and all state they do not use API data for model training by default. However, you are responsible for ensuring that the DPA terms of whichever provider you use align with your GDPR obligations, that data is not retained beyond your requirements, and that you have a lawful basis for the processing. Airparser processes data under GDPR-compliant terms with AES-256 encryption, configurable data retention periods, a DPA, and a no-model-training policy. For organizations in regulated industries or with specific compliance requirements, the compliance documentation differs between the two approaches, and legal review of the applicable DPA terms is recommended before processing personal data at scale. Related: Document Parsing and GDPR: What Compliance Actually Means for Your Workflow.
At what point does it make sense to switch from a raw LLM API to Airparser?
Volume is not actually the determining factor — team type and engineering capacity are. A 10-person engineering team processing 200 invoices/month that has an LLM pipeline already in place can reasonably maintain a custom LLM invoice parser with minimal incremental overhead. A 3-person finance team at a logistics company processing 2,000 invoices/month from hundreds of different suppliers has no developer capacity to build or maintain extraction infrastructure — Airparser at $149/month is clearly the right call. The break-even calculation that matters most: what is one developer-hour worth at your company, and how many developer-hours does building and maintaining your own pipeline actually cost? At standard market rates, one month of a developer's 20% maintenance time (~$1,500–$3,000/month) exceeds Airparser's Business plan price. For most non-engineering teams, the subscription cost is cheaper than the engineering cost at any volume above zero. For engineering teams who are already building an LLM application, the incremental cost of adding invoice extraction is lower — but the reliability and compliance gap remains. Related: Document parsing: build vs. buy — LLM API vs. Airparser.




