Vision Engine Document Parsing: How AI Reads Documents the Way Humans Do
A vision engine processes a document as an image — interpreting layout, structure, and meaning the way a human reader does, not character by character. This is why Airparser can parse anything: scanned invoices, handwritten forms, complex tables, variable layouts.

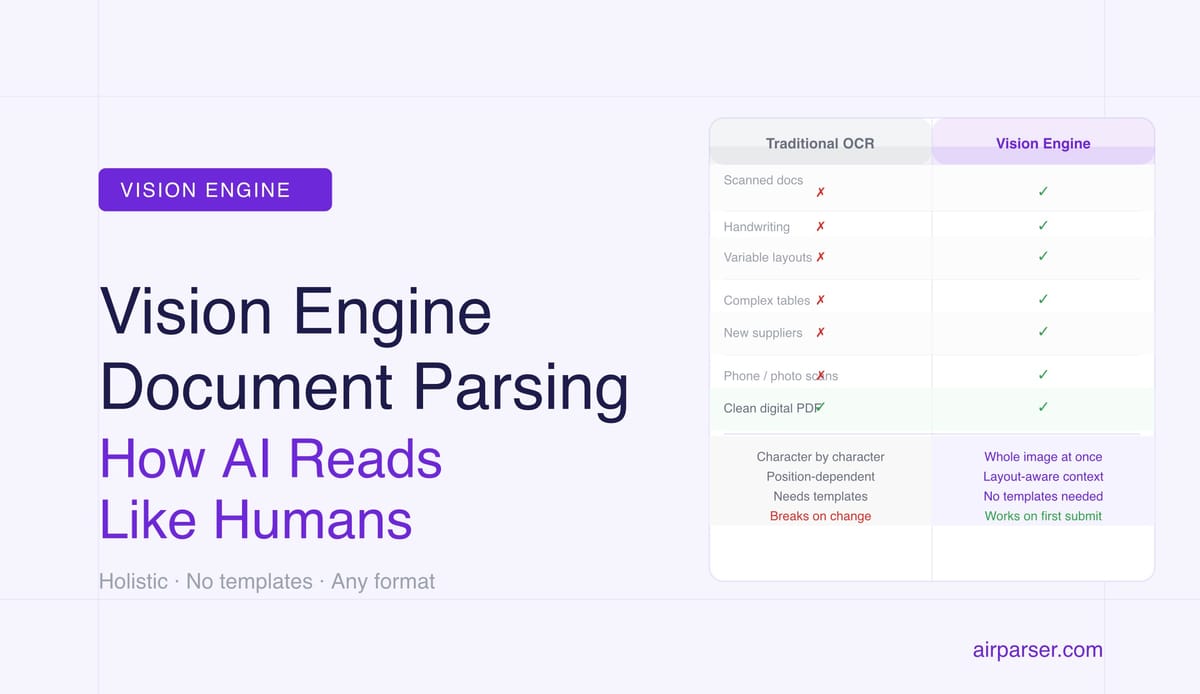
TL;DR: A vision engine reads documents the way a human does — by looking at the whole image, understanding layout, context, and visual structure, not by converting characters one by one. This is why it handles scanned invoices, handwritten forms, complex tables, and variable layouts that break every other approach. Airparser is built on vision engine technology as its default extraction layer.
When you look at an invoice, you don't read it left to right, character by character. You glance at the page, immediately understand the layout, locate the total at the bottom, find the vendor name at the top, and identify the line items in the table in the middle. You understand context. You see relationships. You interpret the document as a whole.
That's exactly what a vision engine does.
Traditional document parsing approaches — OCR, template-based extraction, classic rule engines — work the other way. They process text as a sequence of characters, match patterns against fixed positions, and break the moment a document doesn't behave exactly as configured. They read. They don't understand.
A vision engine processes the raw image of a document — every pixel — and applies the same kind of contextual, visual reasoning a human reader uses. It's the technology behind Airparser's extraction capability, and it's why Airparser can parse documents that other tools can't.
What a Vision Engine Actually Sees
Give a vision engine a scanned invoice. It doesn't run OCR to get the text first. It looks at the image — the entire page, as pixels — and begins to understand its structure the way you would.
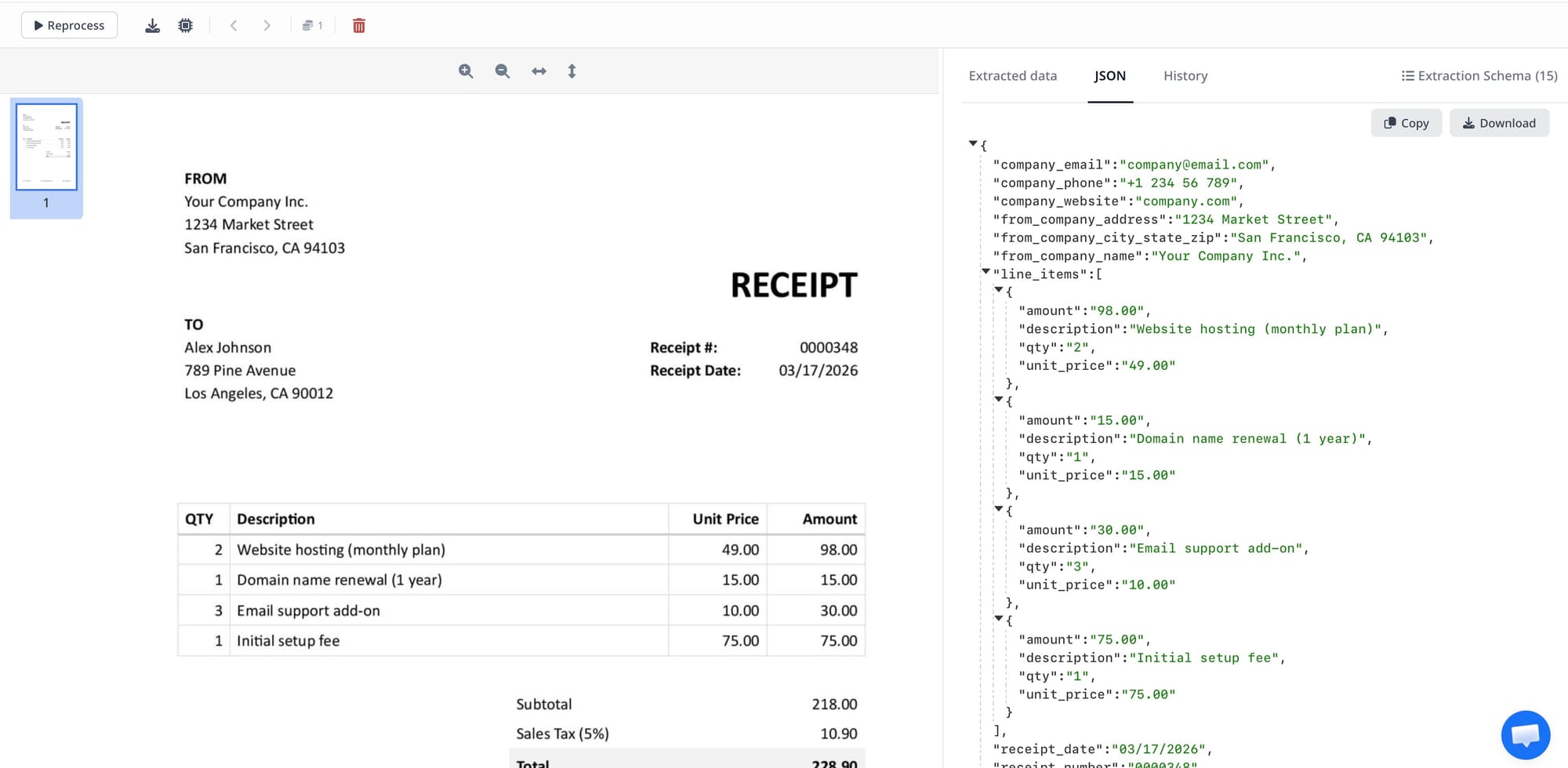
It sees that there are two columns in the header area. It recognizes that the larger text at the top is probably a company name or document title. It identifies a table structure in the middle of the page — rows and columns, with values that are likely product descriptions and prices. It locates a summary section near the bottom with totals. It reads a due date near the top right.
None of this is template-driven. There are no rules telling the engine where to look. It reasons about the document's structure from visual evidence — the same way you do when you pick up an invoice you've never seen before from a supplier you've never worked with, and immediately know where to find the total.
Why Traditional Approaches Can't Do This
OCR was invented to digitize printed text. It does that specific job well. What it doesn't do is understand what the text means, how it relates to other text nearby, or what the document is trying to communicate. OCR converts pixels to characters. That's its complete job description.
Template-based parsers built on top of OCR add a layer: "take the characters OCR found and look for the ones in this specific rectangle on this specific page." This works for documents that never change — utility bills from one provider, payslips from one system, forms from one government office. The moment the layout shifts — a supplier updates their invoice design, a new vendor joins, a form is redesigned — the template breaks and nothing is extracted correctly.
Rule-based systems add another layer of complexity but not fundamental capability. They still depend on text that was correctly OCR'd and positions that match the rules. The core limitation remains: they process text as characters in positions, not as meaning in context.
A vision engine removes the foundational constraint. It doesn't need positions, because it understands context. It doesn't need clean OCR output, because it reads the image directly. It doesn't need templates, because it reasons about document structure from visual evidence.
What This Means in Practice
The practical difference between a vision engine and traditional approaches shows up in the documents that matter most — the ones that are hardest to process automatically.
A scanned invoice from a new supplier. OCR reads the characters. A template parser looks in the wrong rectangles because this supplier uses a different layout. The vision engine looks at the document, identifies the table structure with line items, locates the total in the summary section, finds the vendor name in the header — and returns clean JSON with all fields populated. No template was required. No training was done. It worked on first submission.
A handwritten intake form. OCR accuracy on handwriting is unreliable to unusable, depending on the writer. A vision engine interprets letter shapes from pixel patterns, applying the same visual reasoning a human uses to read someone's handwriting. It handles the variability that defeats character-pattern matching.
A multi-page contract with a signature page. OCR returns pages of text. A vision engine understands that the signature block at the bottom of page 14 is structurally different from the clause text above it, that the date next to the signature is the execution date, and that the party names in the signature block match the parties defined in the opening paragraphs.
An invoice photographed with a smartphone. Slightly skewed, ambient lighting, some blur at the edges. OCR fails on the peripheral text. The vision engine, processing the full image, handles the perspective distortion and degraded quality the way a human reading the photo would — with slightly less certainty on the blurred parts, but still able to extract the core fields correctly.
The Human Analogy Is Precise, Not Metaphorical
The comparison to human vision isn't just a convenient analogy — it's technically accurate about how vision language models work.
Humans read documents by combining two processes: visual perception (what do I see on the page?) and semantic understanding (what does it mean?). We don't read left to right, decode each character in sequence, and then figure out meaning at the end. We perceive visual structure and meaning simultaneously. We see that something is a table before we read what's in it. We recognize a signature as a signature even if we can't read whose it is.
Vision language models are trained to combine these processes in the same way. They process pixel data through vision encoders that recognize visual structures — layouts, tables, figures, handwriting patterns — and simultaneously apply language model understanding to interpret what those structures mean. The result is something much closer to how a human processes a document than anything OCR or template matching produces.
This is why vision engine technology is not an incremental improvement on OCR. It's a different approach to the same problem. Related: Comparing AI extraction methods: traditional OCR vs LLM parsing.
Why Airparser Is Built on Vision Engine Technology
Airparser uses a vision engine as its default extraction layer because it produces better results on the documents real businesses actually process. Not clean PDFs generated by accounting software — those are the easy case. Real-world document automation deals with scanned invoices from suppliers with different formats, photographed receipts from expense claims, handwritten forms from field operations, contracts from different legal teams, and ID documents from identity verification workflows.
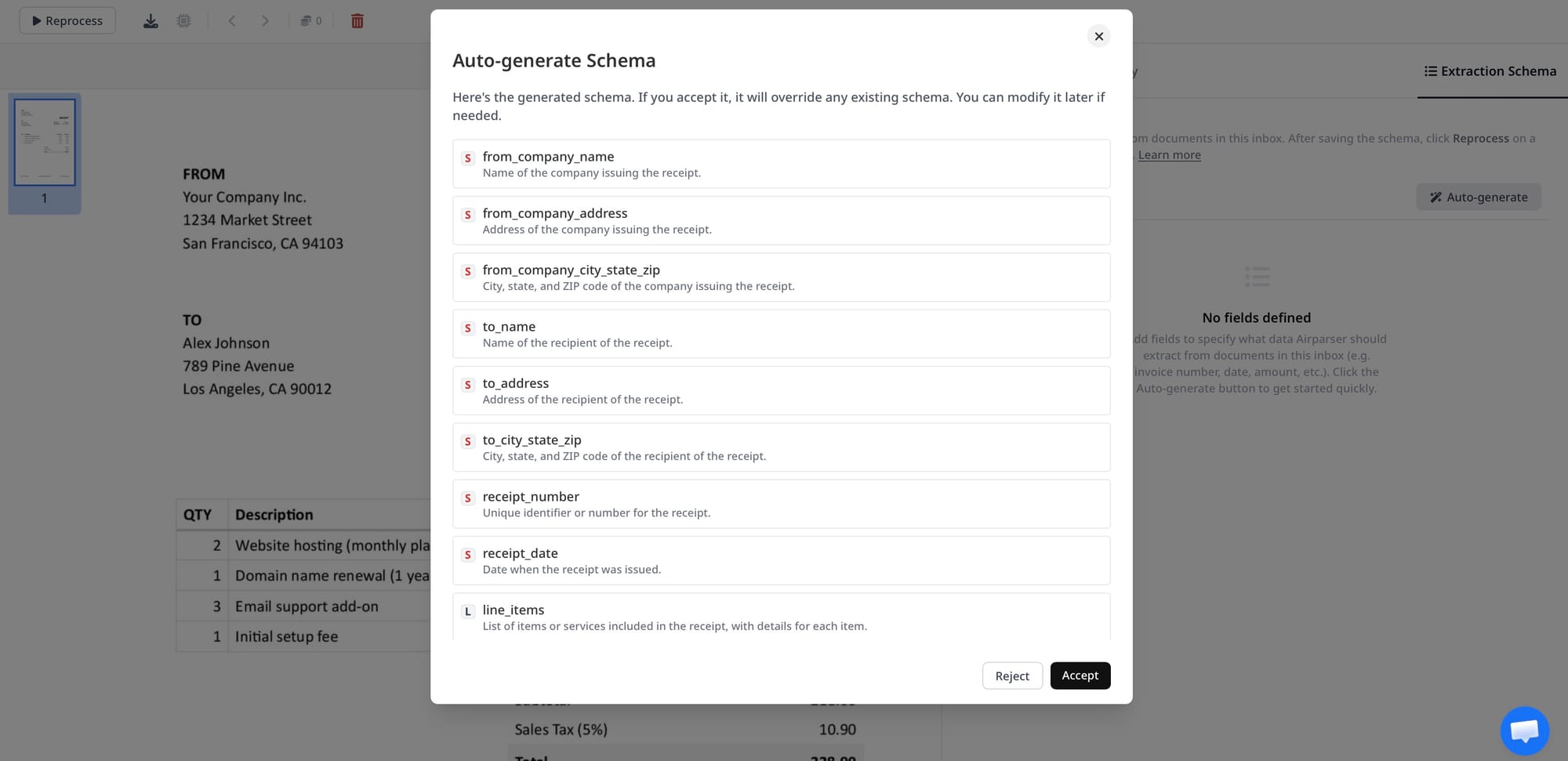
For these documents, vision engine extraction is simply more reliable than the alternatives. No templates to build and maintain. No training data to label and manage. No failure modes caused by layout changes. Submit the document, define the fields you want, get structured JSON back. That works the same way for the first invoice from a new supplier as it does for the ten-thousandth.
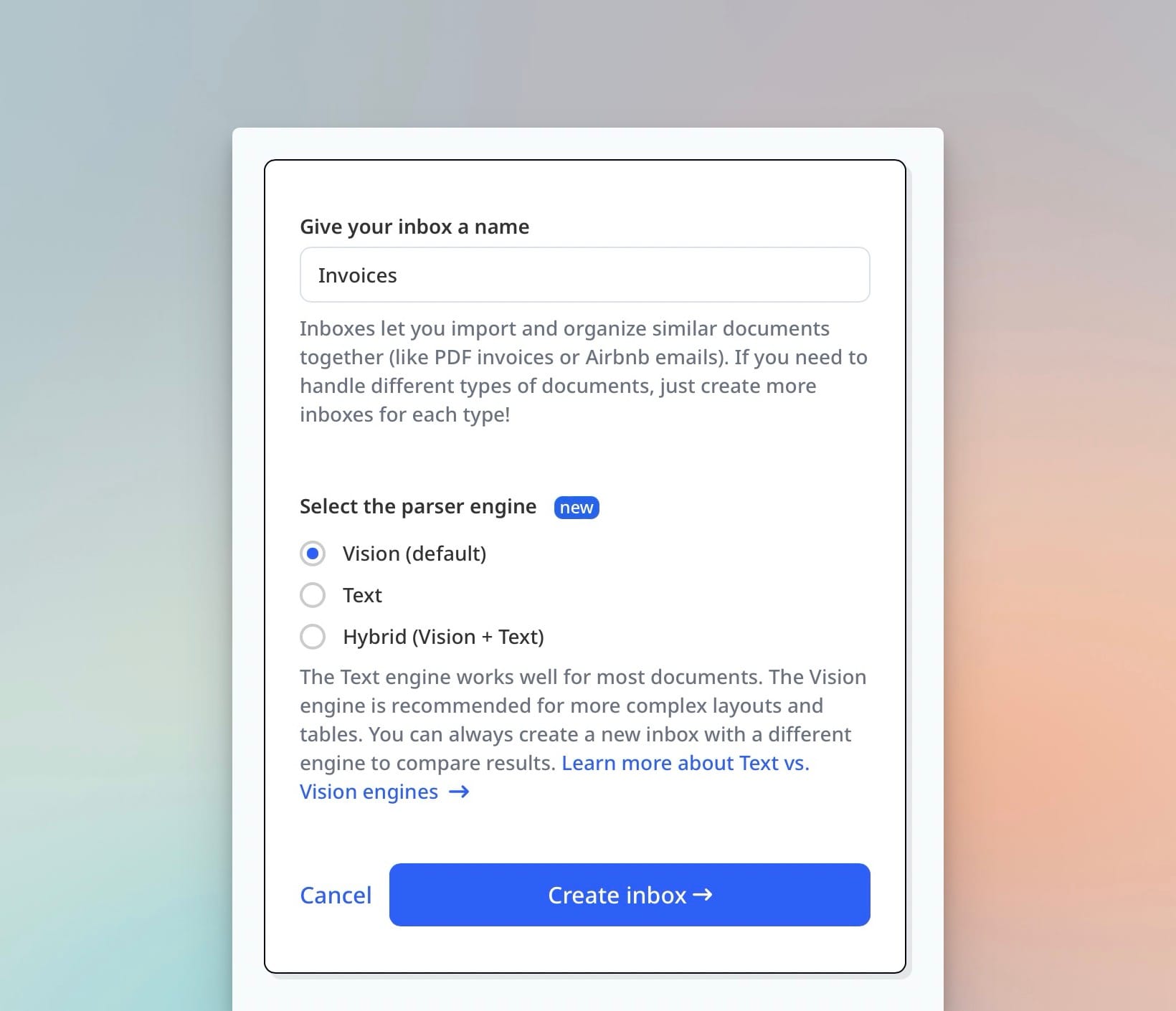
The multi-engine routing in Airparser handles cost and performance automatically: native PDFs with clean text are processed efficiently without vision overhead; image-based and handwritten documents go to the vision engine; complex cases combine both. You define what to extract. Airparser handles how. Related: What is a vision engine in document parsing.
Frequently Asked Questions
Is a vision engine the same as AI OCR?
No — and the distinction matters. "AI OCR" typically refers to OCR systems enhanced with machine learning to improve character recognition accuracy. They still fundamentally read characters. A vision engine is architecturally different: it processes document images holistically, understanding layout, structure, and meaning from visual context rather than building up from individual characters. AI OCR improves how accurately individual characters are identified. A vision engine changes how documents are understood — reading them as spatial, structured visual objects rather than sequences of characters. Airparser's vision engine is not an enhanced OCR system; it's a vision language model that interprets documents as a human reader would.
Does a vision engine work on documents in any language?
Yes. Because a vision engine processes the visual representation of text rather than relying on language-specific character models or dictionaries, it handles multilingual documents, mixed-language documents, and documents in scripts that traditional OCR systems handle poorly — Arabic, Chinese, Japanese, Cyrillic, and others. Airparser supports 60+ languages across document types. For documents where the same invoice might arrive in English from a US supplier and in French from a European one, the same extraction schema works without modification.
Why don't all document parsing tools use vision engines?
Vision engine technology became practically deployable with the maturation of large vision language models in 2023–2024. Before that, accurate visual document understanding at production scale wasn't feasible with available infrastructure. Many document parsing tools were built before this technology existed and are architecturally based on OCR and template matching — adding a vision engine would require rebuilding the extraction pipeline from scratch, not adding a feature. Airparser built its extraction architecture around vision engine technology from the start, which is why it's the default approach rather than an add-on. Template-based tools from the pre-LLM era are adding AI features incrementally, but vision engine document understanding isn't something you bolt on top of an existing template parser.
What are the limitations of vision engine document parsing?
Vision engine processing is more computationally intensive than OCR, which means higher per-document cost and slightly higher latency — extraction takes seconds rather than milliseconds. For extremely high-volume pipelines processing millions of identical clean-text PDFs, OCR-only approaches are more cost-efficient. Vision engines also occasionally produce lower-confidence results on severely degraded documents — very low-resolution scans, heavily water-damaged paper, extreme skew — where the visual input is simply too degraded for reliable interpretation. And like all LLM-based systems, vision engine extraction can occasionally hallucinate a plausible-but-incorrect field value on ambiguous documents, which is why confidence scores and validation steps matter for production workflows. Airparser exposes confidence per extraction so you can route low-confidence results to human review rather than letting them propagate downstream.
How is vision engine technology different from what Parseur or other tools offer?
Many document parsing vendors now claim vision AI capabilities, typically added after the technology became available in 2023–2024. The meaningful distinction is whether vision engine processing is the foundational extraction architecture or an optional add-on applied to specific document types. In Airparser, the vision engine is the default extraction layer — every document is processed with it unless text-only processing is demonstrably sufficient. This architectural choice means the full capability of visual document understanding is applied consistently, not selectively. Tools built on template or OCR architectures that have added vision AI as a feature typically apply it only to documents that fail their primary approach, limiting the coverage and consistency of vision engine benefits. Related: Best document parsing tools in 2026.




