Why Airparser is a great Tabula alternative?
What is a PDF table extraction tool?
A PDF table extraction tool is software that helps you pull tabular data from PDF files, converting tables into structured formats like CSV or Excel. Instead of manually copying and pasting table data, these tools automatically detect table structures and extract the information you need.
Modern PDF table extraction tools use AI and machine learning to understand table layouts, handle complex structures, and preserve data relationships. Best extraction tools can process PDFs, images, and scanned documents automatically.
What is Tabula?
Tabula is an open-source tool designed to extract tables from PDF documents. It's particularly useful for pulling tabular data from PDFs and converting it into CSV or Excel formats. Tabula uses a point-and-click interface where users manually select table areas in PDFs for extraction.
Tabula is free and open-source, making it popular among users who need basic table extraction capabilities. It works well for PDFs with clearly defined table structures and can handle multiple tables within a single document.
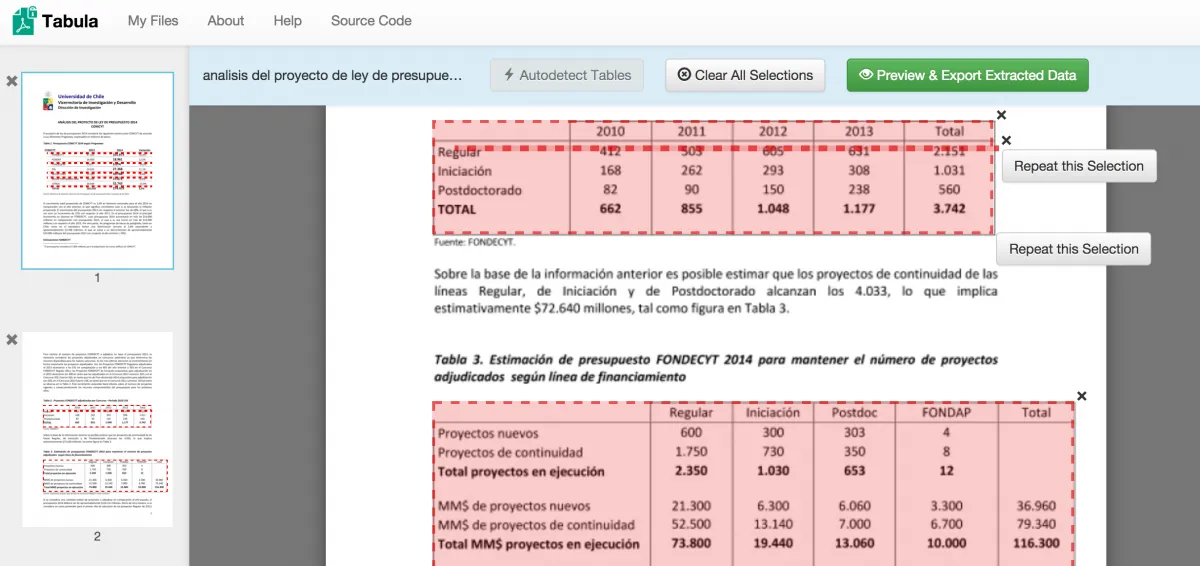
However, Tabula requires manual selection of table areas, which can be time-consuming for large batches of documents. It also works best with PDFs that have text-based tables (not scanned images) and may struggle with complex layouts, merged cells, or tables that span multiple pages. Additionally, Tabula focuses solely on table extraction and doesn't support extracting other types of structured data from documents.
What makes Airparser a great alternative to Tabula?
Airparser uses a smart LLM engine that can automatically detect and extract tables from PDFs without requiring manual selection. This is a big plus compared to Tabula's approach, which requires users to manually click and select table areas for each document.
With Airparser, you can easily extract tables, forms, invoices, and other structured data from PDFs, emails, and images without having to manually configure extraction areas. It works with scanned documents, complex layouts, and even handwritten text, extracting the specific data you need automatically.
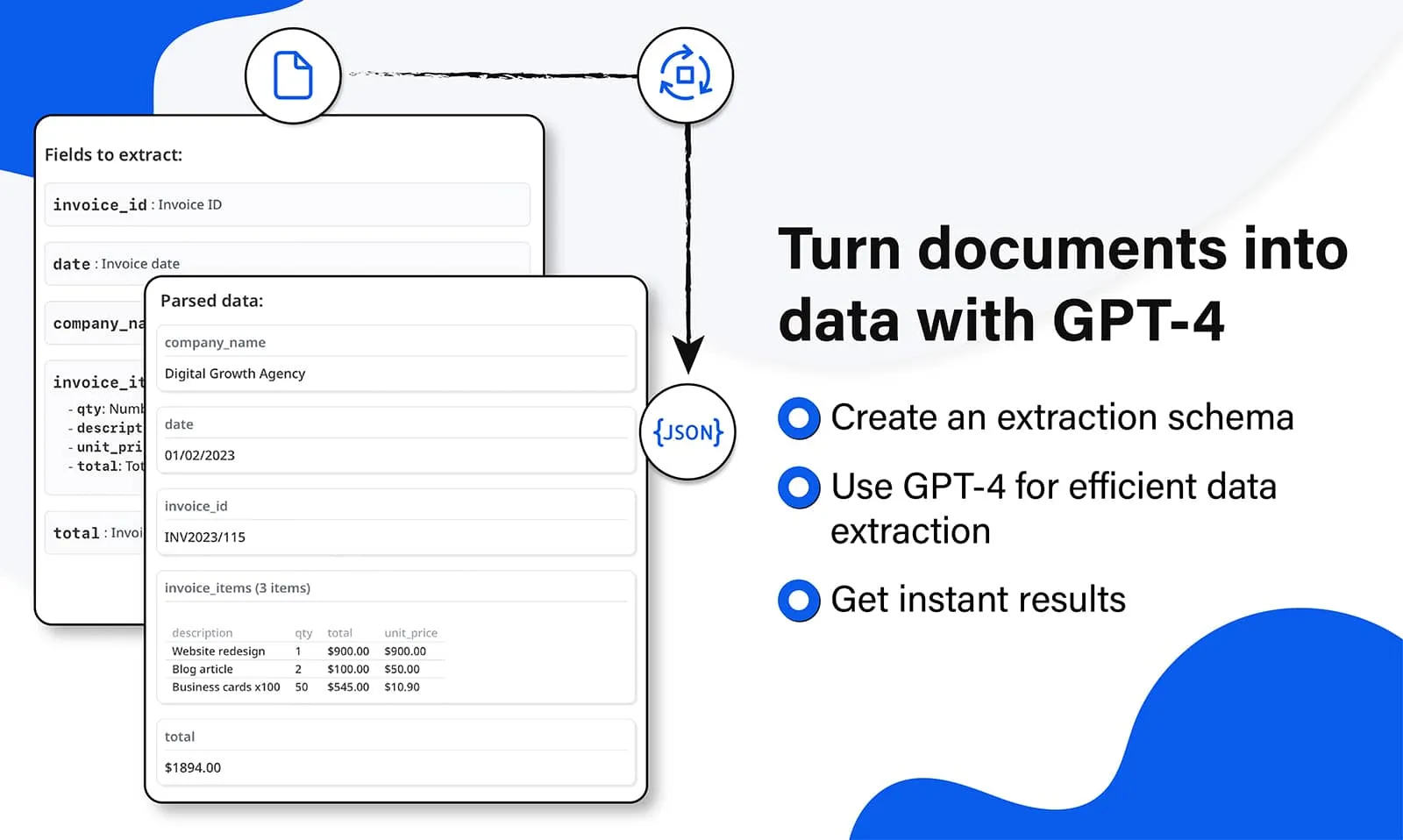
Airparser offers a user-friendly web interface and cloud-based solution, making it accessible from anywhere without requiring software installation. This makes it a great choice for businesses that want to speed up their document processing and extract structured data automatically without the manual work required by Tabula.
Airparser offers a powerful API and seamless integrations. This allows you to connect it easily with your existing tools and systems through Zapier, Make, and direct API access, unlike Tabula which is primarily a desktop application.
Tabula and Airparser compared
Although both Tabula and Airparser can extract tables from PDFs, there are several key differences between them. Here are some of the most important distinctions to help you determine which software is best suited for automating your data extraction needs.
| Tabula | Airparser | |
|---|---|---|
| Price | Free (open-source) | Pay-per-use, flexible pricing |
| Parsing engine | Manual selection-based | LLM-powered (automatic) |
| Extraction method | Manual point-and-click | Automatic AI extraction |
| Parse emails | ||
| Parse PDFs | ||
| Web page & HTML parsing | ||
| Parse scanned PDFs | Limited (text-based PDFs only) | |
| Parse handwritten text | ||
| Supported formats | PDF only (text-based) | Emails, PDFs, HTML, TXT, JPG, PNG, Word, and more |
| Batch processing | Requires manual selection for each PDF | Fully automatic batch processing |
| How easy to configure | Manual: Requires clicking and selecting table areas | Easy: Simply list fields to extract |
| OCR | ||
| Parse tables and lists | ||
| Parse other document types | ||
| Human-in-the-loop review | Fully manual tool — every document is "reviewed" by hand | AI parses, humans review only flagged documents |
| API | Limited (command-line only) | Yes, advanced REST API |
| Webhooks | ||
| Zapier integration | ||
| Make integration | ||
| Cloud-based | Desktop application | |
| User interface | Desktop application (point-and-click) | Modern web interface |
| Data post-processing, validation | ||
| Extract structured data beyond tables |
Everything you need to know
What is manual table selection?
Manual table selection means you need to click and drag to select table areas in each PDF document before extraction.
Pros of manual selection
It gives you control over which tables to extract and works well for simple, clearly defined tables.
Cons of manual selection
It's time-consuming for large batches, requires manual work for each document, and doesn't work well with scanned PDFs or complex layouts.
How does manual selection compare to automatic AI extraction?
Manual selection requires user interaction for each document, while automatic AI extraction processes documents without manual intervention, handling complex layouts and multiple document types.
What types of documents can Airparser handle?
Airparser can handle a wide range of documents including emails, PDFs, images, scanned documents, and even handwritten text, extracting tables and other structured data automatically.
Can Airparser be integrated with other tools?
Airparser seamlessly integrates with over 7000 apps and tools through APIs and no-code automation platforms like Zapier and Make, unlike Tabula which is primarily a desktop tool.
Just a few of the companies already using Airparser
The AI schema creator made it quite literally a 60 second job.
NKNick K.
Family Owner, Retail
on Capterra
The Right Product for quick integration of smart extraction of data from PDF.
Marty N.
CEO, Information Technology
on Capterra
Airparser Makes Email Parsing Effortless With LLM-Powered Engine
Emily C.
Content Director
on Capterra
Which is better, Tabula or Airparser?
Tabula is a free, open-source tool that works well for users who need basic table extraction from text-based PDFs and don't mind manually selecting table areas. It's particularly useful for one-off extractions or small-scale projects where cost is a primary concern.
However, Airparser offers more automation and versatility. Its LLM-powered engine can automatically detect and extract tables without requiring manual selection, making it particularly useful for businesses processing large volumes of documents or needing batch processing capabilities.
Airparser also has significant advantages when it comes to document types and formats. While Tabula focuses only on text-based PDF tables, Airparser can extract structured data from emails, PDFs, images, scanned documents, and even handwritten text automatically.
If you need a tool that can process documents automatically without manual intervention, handle complex layouts and scanned documents, and integrate with other business tools, Airparser could be the optimal solution for your document processing needs, even if it comes with a cost compared to Tabula's free model.
Why Airparser over building it yourself with an LLM API?
Today, it's trivially easy to throw a document at ChatGPT or Claude and get some data back. But production document extraction is a different problem — and the gap between a quick demo and a reliable workflow is where Airparser lives.
Consistent schema output
Raw LLM responses vary. Airparser enforces a strict JSON schema per inbox — same field names, same types, every time. Your downstream systems can rely on the structure.
Webhook & integration pipeline
Airparser delivers results via webhooks, API, Zapier, Make, n8n, Google Sheets, and email — automatically. With a raw LLM, you build and maintain all of that yourself.
Error handling & retries
LLMs fail, time out, and hallucinate. Airparser has multi-engine fallback (text LLM + vision LLM + OCR), automatic retries, and error logging built in — so documents don't silently drop.
Multi-engine fallback
If text extraction fails, Airparser falls back to vision LLM. If that fails, OCR. Each engine handles different edge cases — scanned documents, low-quality images, unusual layouts.
GDPR compliance by default
Airparser provides AES-256 encryption, configurable data retention, no training on your data, and a DPA for enterprise customers. Calling a raw LLM API means managing all of this compliance yourself.
No prompt maintenance
Prompts break when document layouts change. Airparser uses a schema-driven approach — you define fields once and the AI adapts automatically, without per-vendor prompt tuning.